直击ElasticSearch作用 1 2 3 4 5 6 ElasticSearch属于Nosql,是一款非关系型数据库,主要用于数据的全文检索. 搜索 Mysql不具备快速搜索海量数据的能力. 强事务控制 redis做数据缓存,降低mysql的压力 数据库排行榜: https:
1. 搜索技术 搜索技术在我们日常生活的方方面面都会用到,例如:
综合搜索网站:百度、谷歌等 电商网站:京东、淘宝的商品搜索 软件内数据搜索:我们用的开发工具,如Idea的搜索功能 这些搜索业务有一些可以使用数据库来完成,有一些却不行。因此我们今天会学习一种新的搜索方案,解决海量数据、复杂业务的搜索。
1.1.数据库搜索的问题 要实现类似百度的复杂搜索,或者京东的商品搜索,如果使用传统的数据库(mysql)存储数据,那么会存在一系列的问题:
性能瓶颈:当数据量越来越大时,数据库搜索的性能会有明显下降。虽然可以通过分库分表来解决存储问题,但是性能问题并不能彻底解决,而且系统复杂度会提高、可用性下降。 复杂业务:百度或京东的搜索往往需要复杂的查询功能,例如:拼音搜索、错字的模糊搜索等。这些功能用数据库搜索难以实现,或者实现复杂度较高 并发能力:数据库是磁盘存储,虽然也有缓存方案,但是并不实用。因此数据库的读写并发能力较差,难以应对高并发场景 但是,并不是说数据库就一无是处。在一些对业务有强数据一致性需求,==事务==需求的情况下,数据库是不可替代的。
只是在海量数据的搜索方面,需要有新的技术来解决,就是我们今天要学习的倒排索引 技术。
1.2.倒排索引 倒排索引是一种特殊的数据索引方式,虽然与数据库存储的数据结构没有太大差别,但是在检索方式上却大不一样。
1 2 3 4 5 新华字典: 目录: 目录就是倒排索引后的产物 根据目录可以快速定位数据所在的位置 主页: 汉字存放的真实位置 数据存储的位置
1.2.1.基本概念 先来看两个概念:
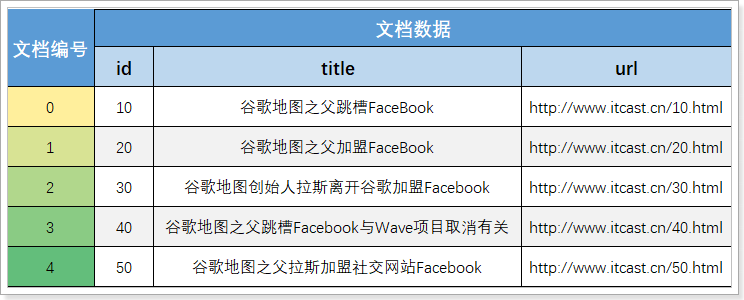
文档(Document):用来检索的海量数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息, 一条记录 词条(Term):对文档数据或用户搜索的数据,利用某种算法分词,得到的具备含义的词语就是词条。 用户搜索时,使用的关键字 例如,数据库中有下面的数据:
那么这里的每一行数据就是一条文档,如:
把标题字段分词,可以得到词语如:谷歌就是一个词条
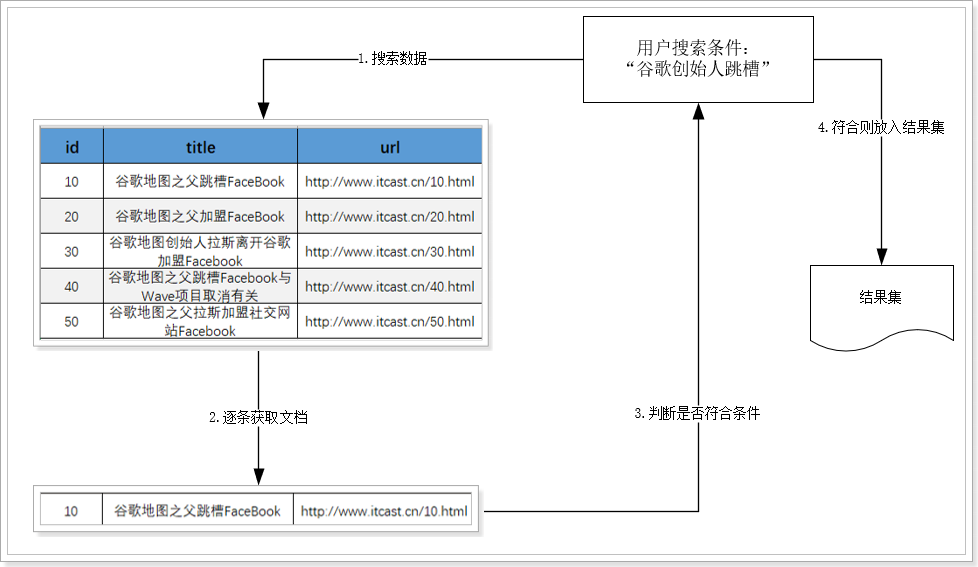
现在,假设用户要搜索"谷歌创始人跳槽",来看看倒排索引的传统查找在检索时的区别:
1.2.1.传统查找流程 因为复杂搜索往往是模糊的查找,因此数据库索引基本都会实效,只能逐条数据判断。基本流程如下:
1)用户搜索数据,条件是title符合"谷歌创始人跳槽"
2)逐行获取数据,比如id为10的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
如图:
如果有5条数据,则需要遍历并判断5次。如果有100万数据,则需要循环遍历和判断100万次。线性查找和判断,效率极差,一个10mb的硬盘文件,遍历一遍需要3秒。
1.2.2.倒排索引流程 倒排索引的数据存储方式与数据库类似,但检索方式不同。
1.2.2.1.数据存储方式 先看看倒排索引如何处理数据。
文档列表 :
首先,倒排索引需要把文档数据逐个编号(从0递增),存储到文档表中。并且给每一个编号创建索引,这样根据编号检索文档的速度会非常快。
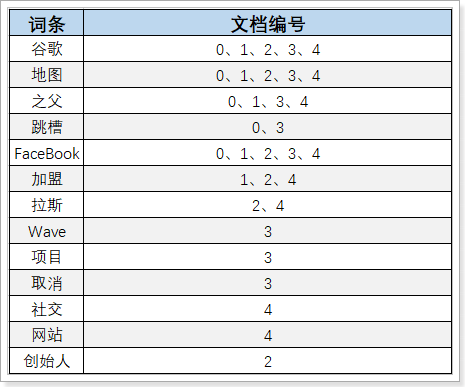
词条列表(Term Dictionary):
然后,对文档中的数据按照算法做分词,得到一个个的词条,记录词条和词条出现的文档的编号、位置、频率信息,如图:
然后给词条创建索引,这样根据词条匹配和检索的速度就非常快。
1.2.2.2.检索数据过程 倒排索引的检索流程如下:
1)用户输入条件"谷歌创始人跳槽"进行搜索。
2)对用户输入内容分词,得到词条:谷歌、创始人、跳槽。
3)拿着词条到词条列表中查找,可以得到包含词条的文档编号:0、1、2、3、4。
4)拿着词条的编号到文档列表中查找具体文档。
如图:
虽然搜索会在两张表进行,但是每次都是根据索引查找,因此速度比传统搜索时的全表扫描速度要快的多。(海量数据之上)
1.3.Lucene 在java语言中,对倒排索引的实现中最广为人知的就是Lucene了,目前主流的java搜索框架都是依赖Lucene来实现的。
Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供 Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具 Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品,比较知名的搜索产品有:Solr、ElasticSearch 官网:http://lucene.apache.org /
企业生产中一般都会使用成熟的搜索产品,例如:Solr或者Elasticsearch,不过从性能来看Elasticsearch略胜一筹,因此我们今天的学习目标就是elasticsearch。
1.4 小结 1 2 3 4 5 6 7 8 9 10 11 倒排索引: 作用: 为了提高检索效率,倒排索引也是一种数据结构,生成的数据也需要存储 实现过程: 文档: 一个网页,一条记录,一片文章 词条: 在搜索数据时使用的关键字 搜索的关键字: 杨梅熟了,梅雨季节来了 对搜索的关键字分词(得到词条): 杨梅 熟了 梅雨 季节 来了 1. 将文档数据进行编号,编号就是文档数据的唯一标识 2. 给要搜索的字段进行倒排索引 对要搜索的字段进行分词,建立词条与文档数据的对应关系 得到的词条与文档数据的对应关系就是--索引库
2.ElasticSearch介绍和安装 如果把Lucene比喻成一台发动机,那么Solr就是一台家用汽车,而Elasticsearch就是一台跑车。
2.1.简介 Elastic官网:https://www.elastic.co/cn/
Elastic是一系列产品的集合,比较知名的是ELK技术栈,其核心就是ElasticSearch:
1 2 3 4 5 ElasticSearch: 检索 Logstash: 日志通道 Kiabana: 图形化界面 日志分析: 分析日志得到用户潜在的需求,从而进行需求实现或优化
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch
1 2 3 4 5 6 JDBC: java操作mysql的技术 面向接口编程(面向规范编程) 面向服务编程: ElasticSearch是一个web服务,当ElasticSearch启动时,就相当于启动了一个web项目. 直接通过浏览器访问即可.遵循RestFul风格的路径,返回json格式的数据
Elasticsearch是一个基于Lucene搜索的web服务 ,对外提供了一系列的Rest风格的API接口。因此任何语言的客户端都可以通过发送Http请求来实现ElasticSearch的操作 。
ES的主要优势特点如下:
速度快 :Elasticsearch 很快,快到不可思议。我们通过有限状态转换器实现了用于全文检索的倒排索引,实现了用于存储数值数据和地理位置数据的 BKD 树,以及用于分析的列存储。而且由于每个数据都被编入了索引,因此您再也不用因为某些数据没有索引而烦心。您可以用快到令人惊叹的速度使用和访问您的所有数据。实现近实时搜索 ,海量数据更新在Elasticsearch中几乎是完全同步的。扩展性高 :可以在笔记本电脑上运行,也可以在承载了 PB 级数据的成百上千台服务器上运行。原型环境和生产环境可无缝切换;无论 Elasticsearch 是在一个节点上运行,还是在一个包含 300 个节点的集群上运行,您都能够以相同的方式与 Elasticsearch 进行通信。它能够水平扩展 ,每秒钟可处理海量事件,同时能够自动管理索引和查询在集群中的分布方式,以实现极其流畅的操作。天生的分布式设计,很容易搭建大型的分布式集群 (solr使用Zookeeper作为注册中心来实现分布式集群)强大的查询和分析 :通过 Elasticsearch,您能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标),搜索方式随心而变。先从一个简单的问题出发,试试看能够从中发现些什么。找到与查询最匹配的 10 个文档是一回事。但如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。如全文检索,同义词处理,相关度排名,复杂数据分析。操作简单 :客户端API支持Restful风格,简单容易上手。目前Elasticsearch最新的版本是7.x.x,我们就使用7.4.2版本,在课前资料中可以找到安装包:
需要JDK1.8及以上(在7.0以后的版本中,自带了jdk)
如果要自己下载,地址:https://mirrors.huaweicloud.com/elasticsearch/
2.2.安装 我们选择在windows下安装。
安装ES的步骤非常简单:
解压:绿色版软件,解压即可使用 配置:修改ES的配置文件中部分属性 启动:运行启动脚本即可启动 1)解压 把课前资料提供的文件解压到某个目录即可,最好不要有中文:
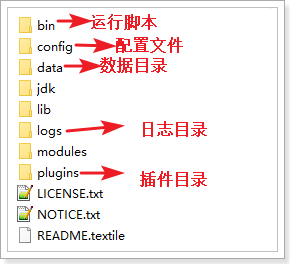
目录结构如下:
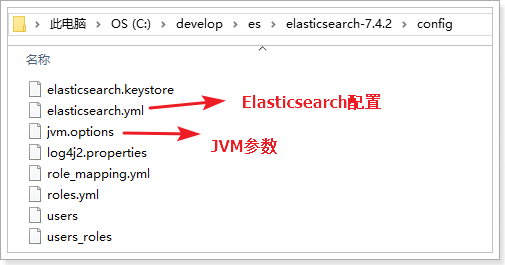
2)修改配置 进入config目录,有下面的配置:
核心是两个配置:
我们打开jvm.options,修改JVM内存参数:
Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数
默认配置如下:
内存占用太多了,我们调小一些:
3)启动 进入安装目录的bin目录:
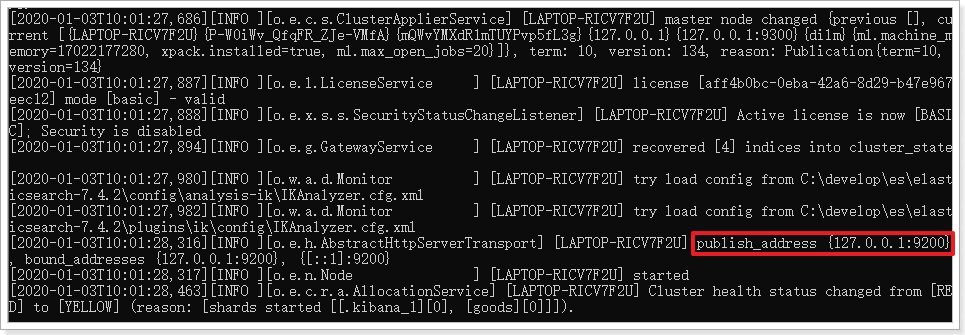
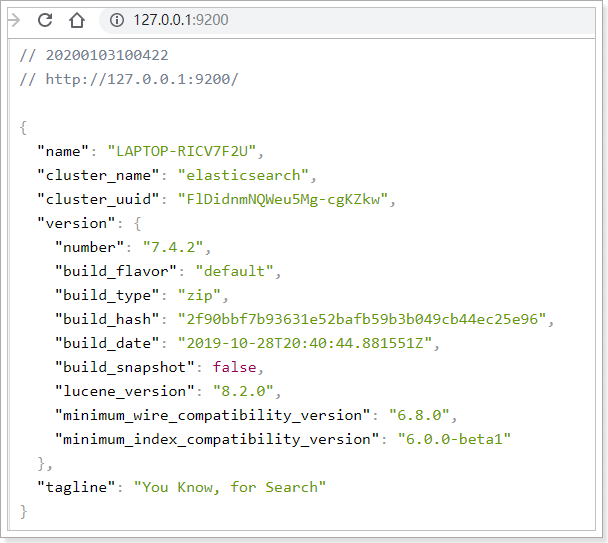
双击elasticsearch.bat文件即可启动。可以看到日志中的IP和端口信息:
在浏览器中访问:http://127.0.0.1:9200
踩坑 elasticsearch8.0.0版本默认开启了强制https认证,如果需要http访问则需要关闭认证
elasticsearch.yml配置:认证相关都改为false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 xpack.security.enabled: false xpack.security.enrollment.enabled: false xpack.security.http.ssl: enabled: false keystore.path: certs/http.p12 xpack.security.transport.ssl: enabled: false verification_mode: certificate keystore.path: certs/transport.p12 truststore.path: certs/transport.p12
Docker安装ElasticSearch7 1 2 3 4 5 6 7 8 9 10 11 12 # docker pull elasticsearch # docker run -d --name elasticsearch-test --net some -p 9200:9200 -p 9300:9300 \ -e "http.host=0.0.0.0" \ -e "discovery.type=single-node" \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "cluster.name=elastic-test" \ -v es7:/usr/share/elasticsearch \ elasticsearch:7.17.0
2.3.Kibana ElasticSearch是一个web服务,但是没有提供图形化界面来操作。因此我们需要安装Kibana,方便学习。
2.3.1.什么是Kibana?
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
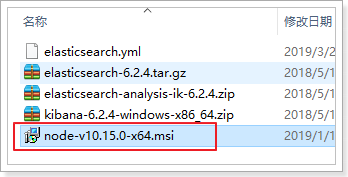
2.3.2.安装NodeJS 因为Kibana依赖于node,需要在windows下先安装Node.js,双击运行课前资料提供的node.js的安装包:
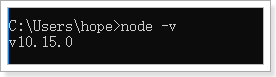
一路下一步即可安装成功,然后在任意黑窗口输入名:
可以查看到node版本,如下:
2.3.3.安装Kibana 课前资料提供了Kibana的安装包:
1)解压 kibana同样是绿色版,解压即可使用:
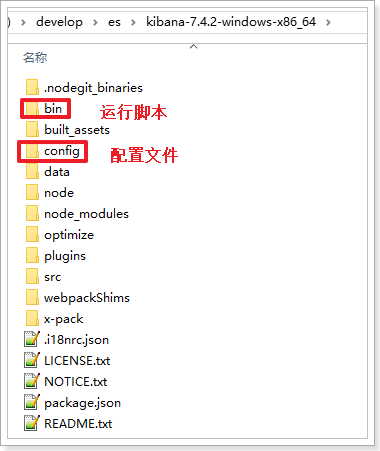
目录结构:
配置ElasticSearch服务地址: Kibana.yml
1 elasticsearch.hosts: ["http://localhost:9200" ]
2)运行 进入bin目录:
双击kibana.bat文件即可
双击运行:
发现kibana的监听端口是5601
我们访问:http://127.0.0.1:5601
3)控制台 Kibana提供了开发工具(devTools)方便我们操作ES,点击左侧菜单即可找到:
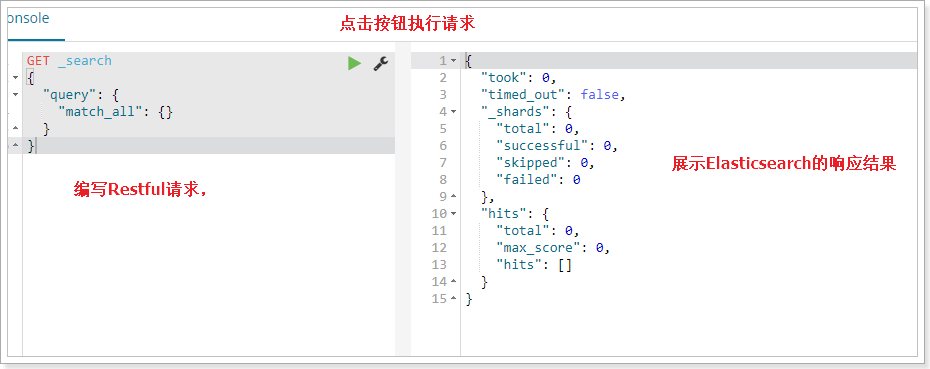
在控制台中,可以方便的向ES发起Http请求:
说明:
GET:代表是发送了一个GET方式的http请求_search:是请求的URL路径,前面省略了localhost:9200{"query": { "match_all": {} } }:是JSON风格的请求参数,这里代表查询所有数据踩坑 1、Kibana版本应该与ElasticSearch版本对应,否则Kibana会启动失败
2、最新版本Kibana对浏览器有限制,需要使用最新版本Chrome浏览器
3.快速入门 接下来快速看下elasticsearch的使用
3.1.概念 Elasticsearch虽然是一种NoSql库,但最终的目的是存储数据、检索数据。因此很多概念与MySQL类似的。
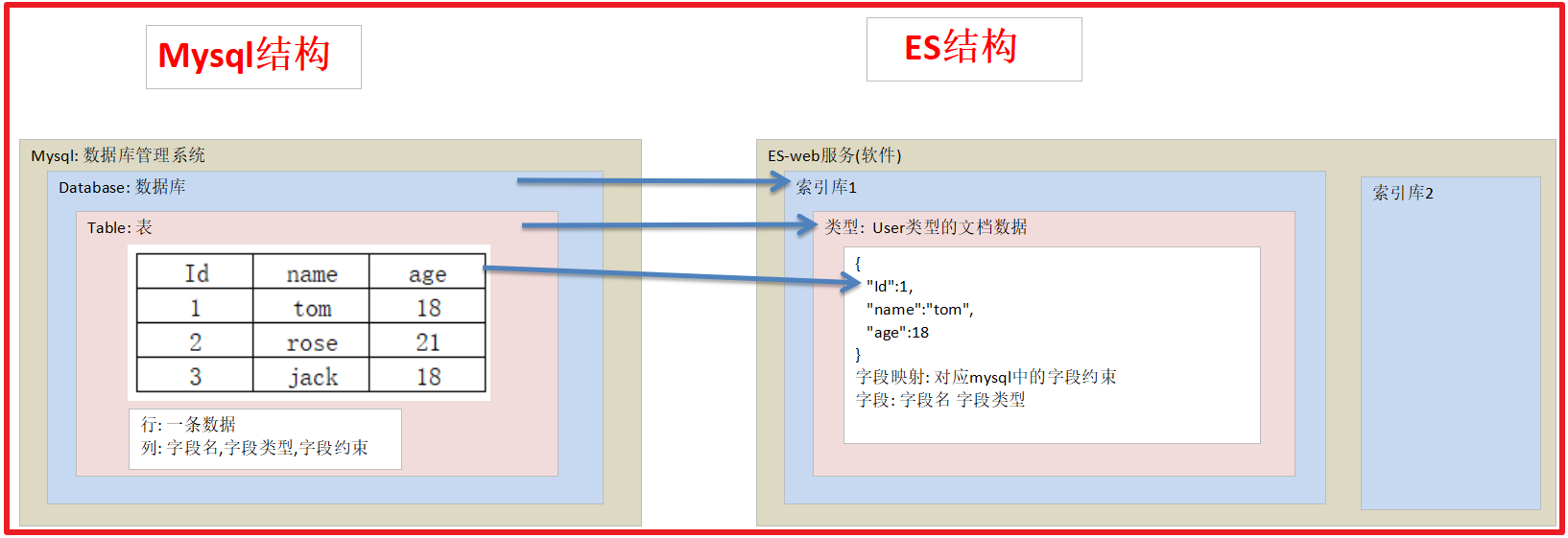
ES中的概念 数据库概念 说明 索引库(indices) 数据库(Database) ES中可以有多个索引库,就像Mysql中有多个Database一样。 类型 表(table) mysql中database可以有多个table,table用来约束数据结构。而ES中的每个索引库中只有一个类型,类型中用来约束字段属性的叫做映射(mapping) 映射(mappings) 表的字段约束 mysql表对字段有约束,ES中叫做映射,用来约束字段属性,包括:字段名称、数据类型等信息 文档(document) 行(Row) 存入索引库原始的数据,比如每一条商品信息,就是一个文档。对应mysql中的每行数据 字段(field) 列(Column) 文档中的属性,一个文档可以有多个属性。就像mysql中一行数据可以有多个列。
因此,我们对ES的操作,就是对索引库、类型映射、文档数据的操作:
索引库操作:主要包含创建索引库、查询索引库、删除索引库等 类型映射操作:主要是创建类型映射、查看类型映射 文档操作:文档的新增、修改、删除、查询
3.2.分词器 根据我们之前讲解的倒排索引原理,当我们向elasticsearch插入一条文档数据时,elasticsearch需要对数据分词,分词到的如何完成呢?
3.2.1.默认的分词器 kibana中可以测试分词器效果,我们来看看elasticsearch中的默认分词器。
在kibana的DevTools中输入一段命令:
1 2 3 4 5 POST /_analyze { "text" : "黑马程序员学习java太棒了" , "analyzer" : "standard" }
请求代表的含义:
效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 { "tokens" : [ { "token" : "黑" , "start_offset" : 0 , "end_offset" : 1 , "type" : "<IDEOGRAPHIC>" , "position" : 0 } , { "token" : "马" , "start_offset" : 1 , "end_offset" : 2 , "type" : "<IDEOGRAPHIC>" , "position" : 1 } , { "token" : "程" , "start_offset" : 2 , "end_offset" : 3 , "type" : "<IDEOGRAPHIC>" , "position" : 2 } , { "token" : "序" , "start_offset" : 3 , "end_offset" : 4 , "type" : "<IDEOGRAPHIC>" , "position" : 3 } , { "token" : "员" , "start_offset" : 4 , "end_offset" : 5 , "type" : "<IDEOGRAPHIC>" , "position" : 4 } , { "token" : "学" , "start_offset" : 5 , "end_offset" : 6 , "type" : "<IDEOGRAPHIC>" , "position" : 5 } , { "token" : "习" , "start_offset" : 6 , "end_offset" : 7 , "type" : "<IDEOGRAPHIC>" , "position" : 6 } , { "token" : "java" , "start_offset" : 7 , "end_offset" : 11 , "type" : "<ALPHANUM>" , "position" : 7 } , { "token" : "太" , "start_offset" : 11 , "end_offset" : 12 , "type" : "<IDEOGRAPHIC>" , "position" : 8 } , { "token" : "棒" , "start_offset" : 12 , "end_offset" : 13 , "type" : "<IDEOGRAPHIC>" , "position" : 9 } , { "token" : "了" , "start_offset" : 13 , "end_offset" : 14 , "type" : "<IDEOGRAPHIC>" , "position" : 10 } ] }
一个字分成一个词,实在是太糟糕了。。
3.2.2.中文分词 标准分词器并不能很好处理中文,一般我们会用第三方的分词器,例如:IK分词器。
IK分词器的 地址:https://github.com/medcl/elasticsearch-analysis-ik, 安装非常简单。
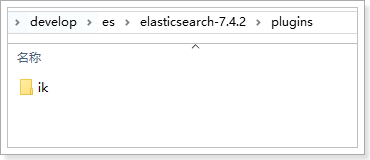
把课前资料中的zip包:
解压到Elasticsearch目录的plugins目录中,并重命名为ik:
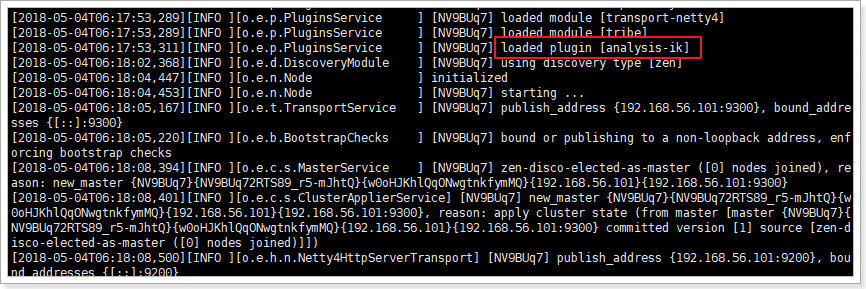
然后重启elasticsearch:
IK分词器加载成功了!
再次运行命令,不过把分词器换成IK:
1 2 3 4 5 POST /_analyze { "text" : "黑马程序员学习java太棒了" , "analyzer" : "ik_smart" }
IK分词器可以用ik_max_word和ik_smart两种方式,分词粒度不同。
效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 { "tokens" : [ { "token" : "黑马" , "start_offset" : 0 , "end_offset" : 2 , "type" : "CN_WORD" , "position" : 0 } , { "token" : "程序员" , "start_offset" : 2 , "end_offset" : 5 , "type" : "CN_WORD" , "position" : 1 } , { "token" : "学习" , "start_offset" : 5 , "end_offset" : 7 , "type" : "CN_WORD" , "position" : 2 } , { "token" : "java" , "start_offset" : 7 , "end_offset" : 11 , "type" : "ENGLISH" , "position" : 3 } , { "token" : "太棒了" , "start_offset" : 11 , "end_offset" : 14 , "type" : "CN_WORD" , "position" : 4 } ] }
3.2.3.Rest的API介绍 操作MySQL,主要是database操作、表操作、数据操作,对应在elasticsearch中,分别是对索引库操作、类型映射操作、文档数据的操作:
索引库操作:主要包含创建索引库、查询索引库、删除索引库等 类型映射操作:主要是创建类型映射、查看类型映射 文档操作:文档的新增、修改、删除、查询 而ES中完成上述操作都可以通过Rest风格的API来完成,符合请求要求的Http请求就可以完成数据的操作,详见官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
下面我们分别来学习。
4.ES的索引库操作 按照Rest风格,增删改查分别使用:POST、DELETE、PUT、GET等请求方式,路径一般是资源名称。因此索引库操作的语法类似。
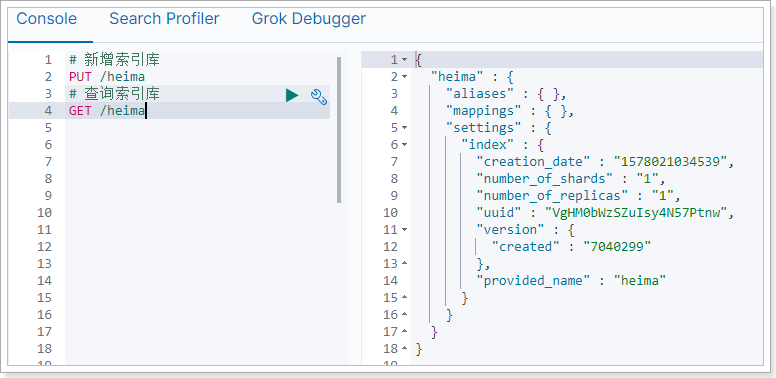
4.1.创建索引库 创建索引库的请求格式:
示例:
1 2 3 4 5 6 put /索引库名{ "settings" : { "属性名" : "属性值" } }
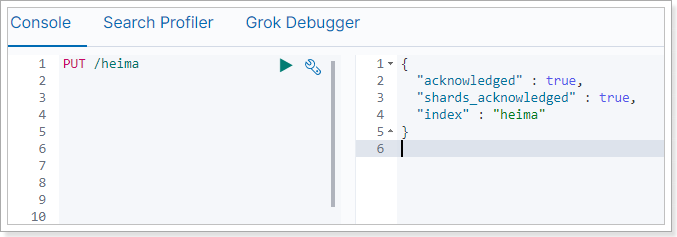
在Kibana中测试一下:
这里我们没有写settings属性,索引库配置都走默认。
4.2.查询索引库 Get请求可以帮我们查看索引信息,格式:
在Kibana中测试一下:
可以看到返回的信息也是JSON格式,其中包含这么几个属性:
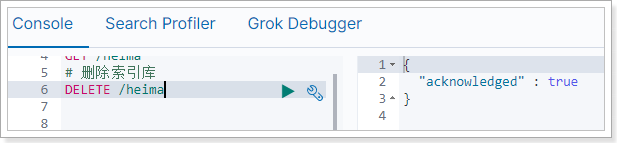
mappings:类型映射,目前我们没有给索引库设置映射 settings:索引库配置,目前是默认配置 4.3.删除索引库 删除索引使用DELETE请求,格式:
在Kibana中测试一下:
4.4.总结 索引库操作:
创建索引库: PUT /库名称 查询索引库: GET /索引库名称 删除索引库: DELETE /索引库名称 1 浏览器(Kibana)客户端在操作ES时,交互的都是json格式的数据信息
5.类型映射 MySQL中有表,并且表中有对字段的约束,对应到elasticsearch中就是类型映射mapping.
5.1.映射属性 索引库数据类型是松散的,不过也需要我们指定具体的字段及字段约束信息。而约束字段信息的就叫做映射(mapping)。
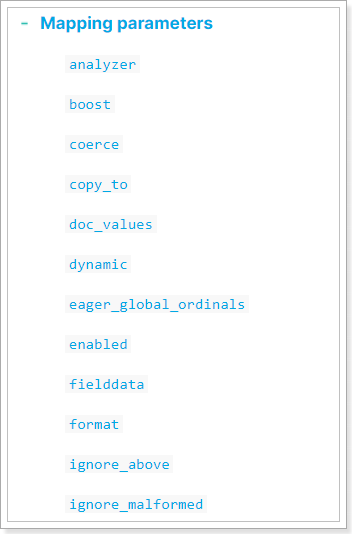
映射属性包括很多:
参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/mapping-params.html
elasticsearch字段的映射属性该怎么选,一般要考虑这样几个问题:
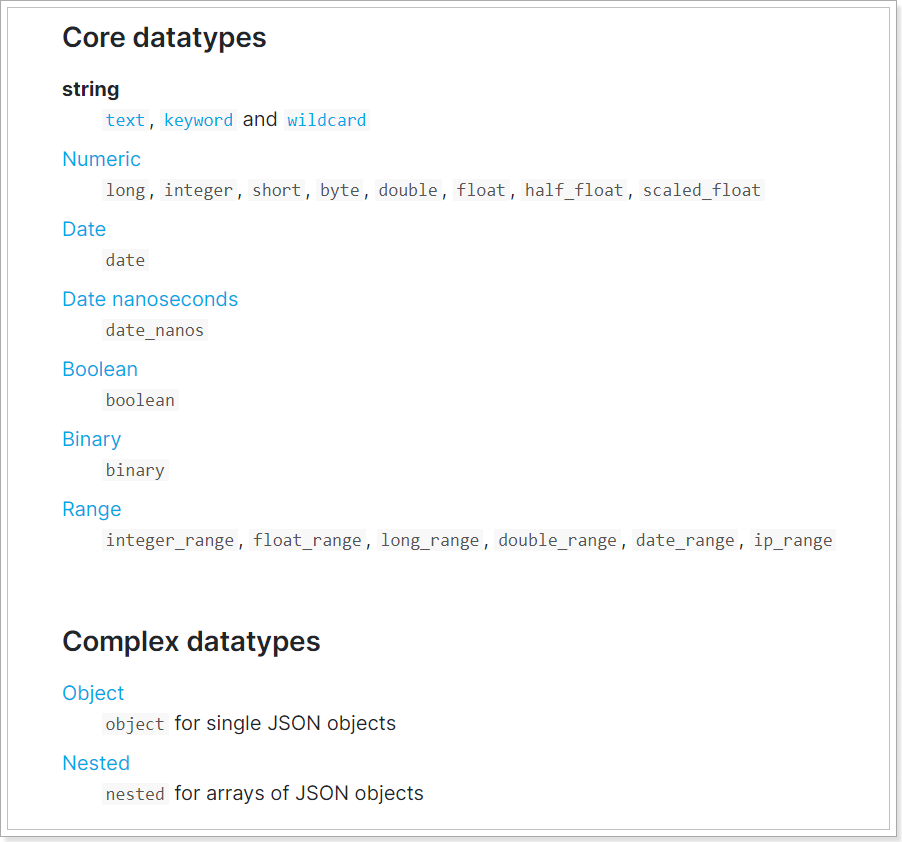
1)数据的类型是什么?这个比较简单,根据字段的含义即可知道,可以通过type属性来指定 2)数据是否参与搜索?参与搜索的字段将来需要创建倒排索引,作为搜索字段。可以通过index属性来指定是否参与搜索,默认为true,也就是每个字段都参与搜索 3)数据存储时是否需要分词?一个字段的内容如果不是一个不可分割的整体,例如国家,一般都需要分词存储。 4)如果分词的话用什么分词器?分词器类型很多,中文一般选择IK分词器 指定分词器类型可以通过analyzer属性指定 5.2.数据类型 elasticsearch提供了非常丰富的数据类型:
比较常见的有:★
比如,我们有这样一个文档数据需要存入ES中:
1 2 3 4 5 6 7 8 9 { "title" : "Apple Iphone11 Pro" , "price" : [ 7999.00 , 8999.00 ] , "images" : "http://www.img.com/1.jpg,http://www.img.com/2.jpg," , "make" : { "name" : "富士康" , "year" : 2019 } }
我们分析下每个字段的数据类型:
title:string类型,将来一定参与搜索,并且内容较多,需要分词,应该使用text类型 price:浮点数。这里可以选择double或float images:string类型,不参与搜索,并且不需要分词。因此应该选择keyword类型。 make:Object类型,需要做扁平化处理,变成两个字段:make.name:string类型,不需要分词,选择keyword类型。 make.year:整数类型,可以选择int。 上面的数据存入ES以后,会变成下面这样:
1 2 3 4 5 6 7 { "title" : "Apple Iphone11 Pro" , # text类型, 参与分词 "price" : [ 7999.00 , 8999.00 ] , # double类型 "images" : "http://www.img.com/1.jpg,http://www.img.com/2.jpg," , # keyword, 不能拆分 "make.name" : "富士康" , # keyword 类型 "make.year" : 2019 # int 类型 }
5.3.创建映射 我们可以给一个已经存在的索引库添加映射关系,也可以创建索引库的同时直接指定映射关系。
5.3.1.索引库已经存在 我们假设已经存在一个索引库,此时要给索引库添加映射。
语法
请求方式依然是PUT
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 PUT /索引库名/_mapping { "properties" : { "字段名1" : { "type" : "类型" , "index" : true "analyzer" : "分词器" } , "字段名2" : { "type" : "类型" , "index" : true "analyzer" : "分词器" } , ... } }
类型名称:就是前面讲的type的概念,类似于数据库中的表type:类型,可以是text、long、short、date、integer、object等 index:是否参与搜索,默认为true analyzer:分词器 示例
发起请求:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 PUT heima/_mapping { "properties" : { "title" : { "type" : "text" , "analyzer" : "ik_smart" } , "images" : { "type" : "keyword" , "index" : "false" } , "price" : { "type" : "float" } } }
响应结果:
1 2 3 { "acknowledged" : true }
上述案例中,就给heima这个索引库添加了一个类型,并且在类型中设置了3个字段:
title:商品标题index:标题一般都参与搜索,所以index没有配置,按照默认为true type: 标题是字符串类型,并且参与搜索和分词,所以用text analyzer:标题内容一般较多,查询时需要分词,所以指定了IK分词器 images:商品图片type:图片是字符串,并且url不需要分词,所以用keyword index:图片url不参与搜索,所以给false price:商品价格type:价格,浮点型,这里给了float index:这里没有配置,默认是true,代表参与搜索 并且给这些字段设置了一些属性:
5.3.2.索引库不存在 如果一个索引库是不存在的,我们就不能用上面的语法,而是这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 PUT /索引库名 { "mappings" : { "properties" : { "字段名1" : { "type" : "类型" , "index" : true "analyzer" : "分词器" } , "字段名2" : { "type" : "类型" , "index" : true "analyzer" : "分词器" } , ... } } }
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 创建索引库和映射 PUT /heima2 { "mappings" : { "properties" : { "title" : { "type" : "text" , "analyzer" : "ik_max_word" } , "images" : { "type" : "keyword" , "index" : "false" } , "price" : { "type" : "float" } } } }
结果:
1 2 3 4 5 { "acknowledged" : true , "shards_acknowledged" : true , "index" : "heima2" }
5.4.查看映射关系 查看使用Get请求
语法:
示例:
响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 { "heima" : { "aliases" : { } , "mappings" : { "properties" : { "images" : { "type" : "keyword" , "index" : false } , "price" : { "type" : "float" } , "title" : { "type" : "text" , "analyzer" : "ik_max_word" } } } , "settings" : { "index" : { "creation_date" : "1590744589271" , "number_of_shards" : "1" , "number_of_replicas" : "1" , "uuid" : "v7AHmI9ST76rHiCNHb5KQg" , "version" : { "created" : "7040299" } , "provided_name" : "heima" } } } }
6.文档的操作 我们把数据库中的每一行数据查询出来,存入索引库,就是文档。文档的主要操作包括新增、查询、修改、删除。
6.1.新增文档 6.1.1.新增并随机生成id 通过POST请求,可以向一个已经存在的索引库中添加文档数据。ES中,文档都是以JSON格式提交的。
语法:
1 2 3 4 POST /{索引库名}/ _doc { "key" :"value" }
示例:
1 2 3 4 5 6 7 # 新增文档数据 POST /heima/_doc { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.00 }
响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "heima" , "_type" : "_doc" , "_id" : "spXlVnoB3K_inZJ-xB6s" , "_version" : 1 , "result" : "created" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 0 , "_primary_term" : 1 }
结果解释:
_index:新增到了哪一个索引库。_id:这条文档数据的唯一标示,文档的增删改查都依赖这个id作为唯一标示。此处是由ES随即生成的,我们也可以指定使用某个ID新增文档时:如果指定了id,并且id在索引库不存在,直接存入索引库;如果id已经存在,则执行修改 修改文档时:先根据id删除指定文档,然后加入新的文档 删除文档时:根据id找到文档,然后删除 result:执行结果,可以看到结果显示为:created,应该是创建成功了。6.1.1.新增并指定id 通过POST请求,可以向一个已经存在的索引库中添加文档数据。ES中,文档都是以JSON格式提交的。
语法:
1 2 3 4 POST /{索引库名}/ _doc/{id} { "key" :"value" }
示例:
1 2 3 4 5 6 7 # 新增文档数据并指定id POST /heima/_doc/1 { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.00 }
响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_version" : 1 , "result" : "created" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 1 , "_primary_term" : 1 }
同样新增成功了!
6.2.查看文档 根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把刚刚生成数据的id带上。
语法:
通过kibana查看数据:
1 GET /heima/_doc/rGFGbm8BR8Fh6kyTbuq8
查看结果:
1 2 3 4 5 6 7 8 9 10 11 12 { "_index" : "heima" , "_type" : "goods" , "_id" : "r9c1KGMBIhaxtY5rlRKv" , "_version" : 1 , "found" : true , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699 } }
6.3.修改文档 把刚才新增的请求方式改为PUT,就是修改了。不过修改必须指定id,
id对应文档存在,则修改 id对应文档不存在,则新增 比如,我们把使用id为3,不存在,则应该是新增:
1 2 3 4 5 6 7 # 新增 PUT /heima/_doc/2 { "title" : "大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2899.00 }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "heima" , "_type" : "_doc" , "_id" : "2" , "_version" : 1 , "result" : "created" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 2 , "_primary_term" : 1 }
可以看到是created,是新增。
我们再次执行刚才的请求,不过把数据改一下:
1 2 3 4 5 6 7 # 修改 PUT /heima/_doc/2 { "title" : "大米手机Pro" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3099.00 }
查看结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "heima" , "_type" : "_doc" , "_id" : "2" , "_version" : 2 , "result" : "updated" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 3 , "_primary_term" : 1 }
可以看到结果是:updated,显然是更新数据
6.4.删除文档 删除使用DELETE请求,同样,需要根据id进行删除:
语法
示例
1 2 DELETE /heima/ _doc/rGFGbm8BR8Fh6kyTbuq8
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "heima" , "_type" : "_doc" , "_id" : "rGFGbm8BR8Fh6kyTbuq8" , "_version" : 2 , "result" : "deleted" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 4 , "_primary_term" : 1 }
可以看到结果result为:deleted,说明删除成功了。
6.5.默认映射 刚刚我们在新增数据时,添加的字段都是提前在类型中通过mapping定义过的,如果我们添加的字段并没有提前定义过,能够成功吗?
事实上Elasticsearch有一套默认映射规则,如果新增的字段从未定义过,那么就会按照默认映射规则来存储。
测试一下:
1 2 3 4 5 6 7 8 9 10 # 新增未映射字段 POST /heima/_doc/3 { "title" : "超大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3299.00 , "stock" : 200 , "saleable" : true , "subTitle" : "超级双摄,亿级像素" }
我们额外添加了stock库存,saleable是否上架,subtitle副标题、3个字段。
来看结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "heima" , "_type" : "_doc" , "_id" : "3" , "_version" : 1 , "result" : "created" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 5 , "_primary_term" : 1 }
成功了!在看下索引库的映射关系:
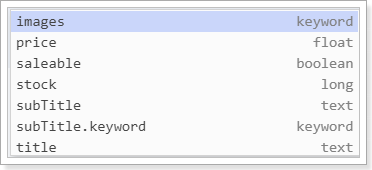
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 { "heima" : { "mappings" : { "properties" : { "images" : { "type" : "keyword" , "index" : false } , "price" : { "type" : "float" } , "saleable" : { "type" : "boolean" } , "stock" : { "type" : "long" } , "subTitle" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } } , "title" : { "type" : "text" , "analyzer" : "ik_max_word" } } } } }
stock、saleable、subtitle都被成功映射了:
stock:默认映射为long类型 saleable:映射为布尔类型 subtitle是String类型数据,ES无法确定该用text还是keyword,它就会存入两个字段。例如:subtitle:text类型 subtitle.keyword:keyword类型 如图:
6.6.动态模板 6.6.1.基本语法 默认映射规则不一定符合我们的需求,我们可以按照自己的方式来定义默认规则。这就需要用到动态模板了。
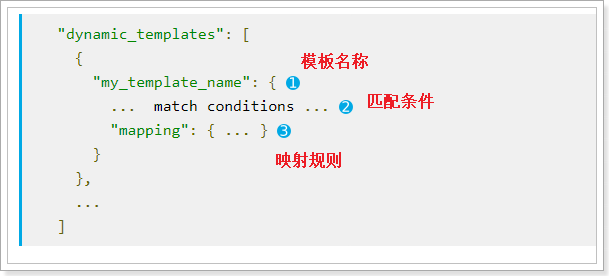
动态模板的语法:
模板名称,随便起 匹配条件,凡是符合条件的未定义字段,都会按照这个mapping中的规则来映射,匹配规则包括:match_mapping_type:按照数据类型匹配,如:string匹配字符串类型,long匹配整型match和unmatch:按照名称通配符匹配,如:t_*匹配名称以t开头的字段 映射规则,匹配成功后的映射规则 凡是映射规则中未定义,而符合2中的匹配条件的字段,就会按照3中定义的映射方式来映射
6.6.2.示例 在kibana中定义一个索引库,并且设置动态模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 动态模板 PUT heima3 { "mappings" : { "properties" : { "title" : { "type" : "text" , "analyzer" : "ik_max_word" } } , "dynamic_templates" : [ { "strings" : { "match_mapping_type" : "string" , "mapping" : { "type" : "keyword" } } } ] } }
这个动态模板的意思是:凡是string类型的字段,统一按照 keyword来处理。
接下来新增一个数据试试:
1 2 3 4 5 6 POST /heima3/_doc/1 { "title" : "超大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3299.00 }
然后查看映射:
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 { "heima3" : { "mappings" : { "dynamic_templates" : [ { "strings" : { "match_mapping_type" : "string" , "mapping" : { "type" : "keyword" } } } ] , "properties" : { "images" : { "type" : "keyword" } , "price" : { "type" : "float" } , "title" : { "type" : "text" , "analyzer" : "ik_max_word" } } } } }
可以看到images是一个字符串,被映射成了keyword类型。
7.查询 首先我们加入2条数据,方便后面的讲解:
1 2 3 4 5 6 7 8 9 10 11 12 13 # 准备测试数据 PUT /heima/_doc/4 { "title" : "小米电视4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3899.00 } PUT /heima/_doc/5 { "title" : "乐视电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.00 }
7.1.基本查询 elasticsearch提供的查询方式有很多,例如:
虽然查询的方式有很多,但是基本语法是一样的:
基本语法
1 2 3 4 5 6 7 8 GET /索引库名/_search { "query" : { "查询类型" : { "查询条件" : "查询条件值" } } }
这里的query代表一个查询对象,里面可以有不同的查询属性
查询类型,有许多固定的值,如:match_all:查询所有 match:分词查询 term:词条查询 fuzzy:模糊查询 range:范围查询 bool:布尔查询 查询条件:查询条件会根据类型的不同,写法也有差异,后面详细讲解 7.1.1 查询所有match_all 示例:
1 2 3 4 5 6 7 # 查询所有 match_all GET /heima/_search { "query" : { "match_all" : { } } }
query:代表查询对象match_all:代表查询所有结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 { "took" : 92 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 5 , "relation" : "eq" } , "max_score" : 1.0 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 1.0 , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "2" , "_score" : 1.0 , "_source" : { "title" : "大米手机Pro" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2999.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "3" , "_score" : 1.0 , "_source" : { "title" : "超大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3299.0 , "stock" : 200 , "saleable" : true , "subTitle" : "超级双摄,亿级像素" } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "4" , "_score" : 1.0 , "_source" : { "title" : "小米电视4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3899.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "5" , "_score" : 1.0 , "_source" : { "title" : "乐视电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.0 } } ] } }
took:查询花费时间,单位是毫秒 time_out:是否超时 _shards:分片信息 hits:搜索结果总览对象total:搜索到的总条数 max_score:所有结果中文档得分的最高分 hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息_index:索引库 _type:文档类型 _id:文档id _score:文档得分 _source:文档的源数据 7.1.2 分词查询match match类型查询,会把查询条件进行分词,然后进行查询,多个词条之间默认是or的关系
语法:
1 2 3 4 5 6 7 8 GET /heima/_search { "query" : { "match" : { "字段名" : "搜索条件" } } }
示例:
1 2 3 4 5 6 7 8 GET /heima/_search { "query" : { "match" : { "title" : "小米电视" } } }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 { "took" : 5 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 3 , "relation" : "eq" } , "max_score" : 1.6748097 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "4" , "_score" : 1.6748097 , "_source" : { "title" : "小米电视4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3899.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 1.0700173 , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "5" , "_score" : 0.68786824 , "_source" : { "title" : "乐视电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.0 } } ] } }
结果中包含3个:”小米电视4A”、”小米手机”、”乐视电视4X”,因为条件中的小米、电视两个词之间是or的关系。
某些情况下,我们需要更精确查找,我们希望这个关系变成and,可以这样做:
1 2 3 4 5 6 7 8 GET /heima/_search { "query" : { "match" : { "title" : { "query" : "小米电视" , "operator" : "and" } } } }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 { "took" : 3 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 1 , "relation" : "eq" } , "max_score" : 1.6748097 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "4" , "_score" : 1.6748097 , "_source" : { "title" : "小米电视4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3899.0 } } ] } }
本例中,只有同时包含小米和电视的词条才会被搜索到。
7.1.3 词条匹配term term 查询,词条查询。查询的条件是一个词条,不会被分词。可以是keyword类型的字符串、数值、或者text类型字段中分词得到的某个词条.
1 2 3 4 5 6 7 8 GET /heima/_search { "query" : { "term" : { "price" : 2699.00 } } }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 1 , "relation" : "eq" } , "max_score" : 1.0 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 1.0 , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } } ] } }
7.1.4.模糊查询fuzzy 首先看一个概念,叫做编辑距离:一个词条变为另一个词条需要修改的次数,例如:
facebool 要修改成facebook 需要做的是把 l 修改成k ,一次即可,编辑距离就是1
模糊查询允许用户查询内容与实际内容存在偏差,但是编辑距离不能超过2,示例:
1 2 3 4 5 6 7 8 9 # 模糊查询 fuzzy GET /heima/_search { "query" : { "fuzzy" : { "title" : { "value" : "小米" , "fuzziness" : 1 } } } }
本例中我搜索的是小米,看看结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 { "took" : 8 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 4 , "relation" : "eq" } , "max_score" : 1.0700173 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 1.0700173 , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "4" , "_score" : 0.83740485 , "_source" : { "title" : "小米电视4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3899.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "2" , "_score" : 0.4697637 , "_source" : { "title" : "大米手机Pro" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2999.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "3" , "_score" : 0.4697637 , "_source" : { "title" : "超大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3299.0 , "stock" : 200 , "saleable" : true , "subTitle" : "超级双摄,亿级像素" } } ] } }
可以看到结果中小米、大米都被搜索到了。
7.1.5.范围查询range range 查询找出那些落在指定区间内的数字或者时间
1 2 3 4 5 6 7 8 9 10 11 12 # 范围查询 GET /heima/_search { "query" : { "range" : { "price" : { "gte" : 1000 , "lt" : 2800 } } } }
range查询允许以下字符:
操作符 说明 gt 大于 gte 大于等于 lt 小于 lte 小于等于
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 2 , "relation" : "eq" } , "max_score" : 1.0 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 1.0 , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "5" , "_score" : 1.0 , "_source" : { "title" : "乐视电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.0 } } ] } }
7.1.6.布尔查询 bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GET /heima/_search { "query" : { "bool" : { "must" : { "match" : { "title" : "小米" } } , "must_not" : { "match" : { "title" : "电视" } } } } }
要小米,但是不要电视
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 1 , "relation" : "eq" } , "max_score" : 1.0700173 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 1.0700173 , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } } ] } }
7.2. 排序 排序、高亮、分页并不属于查询的条件,因此并不是在query内部,而是与query平级,基本语法:
1 2 3 4 5 6 7 8 9 10 11 GET /{ 索引库名称} /_search { "query" : { ... } , "sort" : [ { "{排序字段}" : { "order" : "{asc或desc}" } } ] }
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 排序 GET /heima/_search { "query" : { "match" : { "title" : "小米电视" } } , "sort" : [ { "price" : { "order" : "desc" } } ] }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 3 , "relation" : "eq" } , "max_score" : null , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "4" , "_score" : null , "_source" : { "title" : "小米电视4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3899.0 } , "sort" : [ 3899.0 ] } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : null , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } , "sort" : [ 2699.0 ] } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "5" , "_score" : null , "_source" : { "title" : "乐视电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.0 } , "sort" : [ 2499.0 ] } ] } }
7.3.高亮 高亮是在搜索结果中把搜索关键字标记出来,因此必须使用match这样的条件搜索。
elasticsearch中实现高亮的语法比较简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET /heima/_search { "query" : { "match" : { "title" : "手机" } } , "highlight" : { "pre_tags" : "<em>" , "post_tags" : "</em>" , "fields" : { "title" : { } } } }
在使用match查询的同时,加上一个highlight属性:
pre_tags:前置标签,可以省略,默认是em post_tags:后置标签,可以省略,默认是em fields:需要高亮的字段title:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空 结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 { "took" : 38 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 3 , "relation" : "eq" } , "max_score" : 0.6587735 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 0.6587735 , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } , "highlight" : { "title" : [ "小米<em>手机</em>" ] } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "2" , "_score" : 0.57843524 , "_source" : { "title" : "大米手机Pro" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2999.0 } , "highlight" : { "title" : [ "大米<em>手机</em>Pro" ] } } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "3" , "_score" : 0.57843524 , "_source" : { "title" : "超大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3299.0 , "stock" : 200 , "saleable" : true , "subTitle" : "超级双摄,亿级像素" } , "highlight" : { "title" : [ "超大米<em>手机</em>" ] } } ] } }
7.4.分页 通过from和size来指定分页的开始位置及每页大小。
语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET /heima/_search { "query" : { "match_all" : { } } , "sort" : [ { "price" : { "order" : "asc" } } ] , "from" : 0 , "size" : 2 }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 5 , "relation" : "eq" } , "max_score" : null , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "5" , "_score" : null , "_source" : { "title" : "乐视电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.0 } , "sort" : [ 2499.0 ] } , { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : null , "_source" : { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.0 } , "sort" : [ 2699.0 ] } ] } }
但是,其本质是逻辑分页,因此为了避免深度分页的问题,ES限制最多查到第10000条。
如果需要查询到10000以后的数据,你可以采用两种方式:
详见文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/search-request-body.html#request-body-search-search-after
7.5.Filter过滤 当我们在京东这样的电商网站购物,往往查询条件不止一个,还会有很多过滤条件:
而在默认情况下,所有的查询条件、过滤条件都会影响打分和排名。而对搜索结果打分是比较影响性能的,因此我们一般只对用户输入的搜索条件对应的字段打分,其它过滤项不打分。此时就不能简单实用布尔查询的must来组合条件了,而是实用filter方式。
示例,比如我们要查询小米手机,同时对价格过滤,原本的写法是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 GET /heima/_search { "query" : { "bool" : { "must" : [ { "match" : { "title" : "小米手机" } } , { "range" : { "price" : { "gt" : 2000 , "lt" : 3200 } } } ] } } }
现在要修改成这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 GET /heima/_search { "query" : { "bool" : { "must" : { "match" : { "title" : "小米手机" } } , "filter" : [ { "range" : { "price" : { "gt" : 2000 , "lt" : 3200 } } } ] } } }
7.6._source筛选(字段) 默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤
7.6.1.直接指定字段 示例:
1 2 3 4 5 6 7 8 9 GET /heima/_search { "_source" : [ "title" , "price" ] , "query" : { "term" : { "price" : 2699 } } }
返回的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 { "took" : 0 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : { "value" : 1 , "relation" : "eq" } , "max_score" : 1.0 , "hits" : [ { "_index" : "heima" , "_type" : "_doc" , "_id" : "1" , "_score" : 1.0 , "_source" : { "price" : 2699.0 , "title" : "小米手机" } } ] } }
7.6.2.指定includes和excludes 我们也可以通过:
includes:来指定想要显示的字段 excludes:来指定不想要显示的字段 二者都是可选的。
示例:
1 2 3 4 5 6 7 8 9 10 11 GET /heima/_search { "_source" : { "includes" : [ "title" , "price" ] } , "query" : { "term" : { "price" : 2699 } } }
与下面的结果将是一样的:
1 2 3 4 5 6 7 8 9 10 11 GET /heima/_search { "_source" : { "excludes" : [ "images" ] } , "query" : { "term" : { "price" : 2699 } } }
总结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 搜索技术: 从海量数据中筛选出用户需要的数据信息. 搜索方式: 传统搜索: 遍历每一行,判断每一行中的数据是否满足条件.(线性搜索) 倒排索引: 先将被搜索的数据进行倒排,建立词条与文档数据的对应关系,将对应关系进行存储 搜索时,先查询索引库,根据查询到的文档编号,查找对应的文档数据. 倒排索引流程: 1. 将被搜索的文档进行编号,编号为文档数据的唯一标识 2. 对被搜索的文档数据进行分词,建立词条与文档数据的对应关系. ElasticSearch: 非关系型数据库的一种 作用: 搜索 ElasticSearch启动后就是一个web服务,提供存储数据和搜索数据的功能. 直接通过浏览器即可操作这个web服务. RestFul风格的路径 GET: 查询 POST: 添加 PUT: 修改 DELETE: 删除 mysql: 关系型数据库 作用: 强事务控制 redis: 非关系型数据库 作用: 做缓存 ------------------------------------ 安装ElasticSearch: 服务 安装Kibana: 图形化界面 ES结构: 操作ES
课堂请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 GET _search { "query" : { "match_all" : { } } } # 测试ES内部默认的分词器 POST /_analyze { "text" : "黑马程序员学习java太棒了" , "analyzer" : "standard" } # IK分词器分词 POST /_analyze { "text" : "杨梅熟了,梅雨季节到了" , "analyzer" : "ik_smart" } POST /_analyze { "text" : "杨梅熟了,梅雨季节到了" , "analyzer" : "ik_max_word" } # ================操作索引库 # 创建索引库 PUT /heima # 查询索引库 GET /heima # 删除索引库 DELETE /heima # ===============类型映射(字段相关说明) # 创建索引库 PUT /heima # 创建类型映射 PUT /heima/_mapping { "properties" : { "title" : { "type" : "text" , "index" : "true" , "analyzer" : "ik_smart" } , "images" : { "type" : "keyword" , "index" : "false" } , "price" : { "type" : "float" } } } # 创建类型映射, 没有索引库的情况下 PUT /heima2 { "mappings" : { "properties" : { "title" : { "type" : "text" , "index" : "true" , "analyzer" : "ik_smart" } , "images" : { "type" : "keyword" , "index" : "false" } , "price" : { "type" : "float" } } } } # 查看类型映射 GET /heima/_mapping GET /heima2/_mapping # ===================文档操作 # 新增文档数据 POST /heima/_doc { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.00 } # 新增文档数据并指定id POST /heima/_doc/1 { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699.00 } POST /heima/_doc/1 { "title" : "小米手机pro" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3699.00 } # 查询文档数据 GET /heima/_doc/2 # PUT表修改, 但我们执行时ES中没有指定id的数据信息, 执行的是新增 PUT /heima/_doc/2 { "title" : "大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2899.00 } # 修改 PUT /heima/_doc/2 { "title" : "大米手机Pro" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3099.00 } # 删除文档数据 DELETE /heima/_doc/2 # =====================默认字段类型映射模板 # 新增未映射字段 POST /heima/_doc/3 { "title" : "超大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3299.00 , "stock" : 200 , "saleable" : true , "subTitle" : "超级双摄,亿级像素" } # 查看类型映射 GET /heima/_mapping # 动态模板 PUT /heima3 { "mappings" : { "properties" : { "title" : { "type" : "text" , "analyzer" : "ik_max_word" } } , "dynamic_templates" : [ { "strings" : { "match_mapping_type" : "string" , "mapping" : { "type" : "keyword" } } } ] } } # 添加携带未类型映射的文档数据 POST /heima3/_doc/1 { "title" : "超大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3299.00 } # 查看类型映射 GET /heima3/_mapping # ===============检索数据 # 初始化数据信息 # 准备测试数据 PUT /heima/_doc/4 { "title" : "小米电视4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3899.00 } PUT /heima/_doc/5 { "title" : "乐视电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.00 } PUT /heima/_doc/6 { "title" : "facebook电视4X" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2499.00 } # 查询所有 match_all GET /heima/_search { "query" : { "match_all" : { } } } # match 匹配 or GET /heima/_search { "query" : { "match" : { "title" : "小米电视" } } } # and GET /heima/_search { "query" : { "match" : { "title" : { "query" : "小米电视" , "operator" : "and" } } } } # 查询的词条不可分词, 作为一个整体去查询 GET /heima/_search { "query" : { "term" : { "price" : 2699.00 } } } # 模糊查询 fuzzy GET /heima/_search { "query" : { "fuzzy" : { "title" : { "value" : "小米" , "fuzziness" : 1 } } } } # 范围查询 GET /heima/_search { "query" : { "range" : { "price" : { "gte" : 1000 , "lt" : 2800 } } } } # bool查询 GET /heima/_search { "query" : { "bool" : { "must" : { "match" : { "title" : "小米" } } , "must_not" : { "match" : { "title" : "电视" } } } } } GET /_analyze { "text" : "小米电视" , "analyzer" : "ik_smart" } GET /heima/_mapping