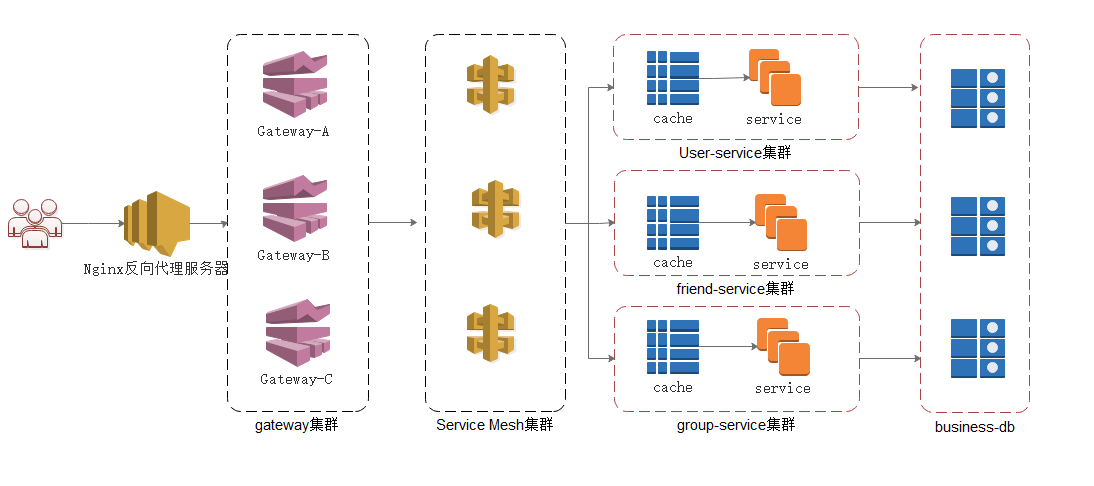
第一章 ShardingSphere 1、ShardingSphere简介 Apache ShardingSphere 是一套开源的分布式数据库 解决方案组成的生态圈。
组成部分: JDBC 、Proxy 和 Sidecar(规划中) 这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。
功能特性:它们均提供标准化的数据水平扩展 、分布式事务 和分布式治理 等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
官方网站:https://shardingsphere.apache.org/index_zh.html
文档地址:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/overview/
本教程主要介绍:Sharding-JDBC和Sharding-Proxy
2、Sharding-JDBC简介
磁盘IO的开销问题,单库情况下无法承载过多的访问 所有的用户数据都存放在同一个表中,mysql单表可以存储 2^32条,但查询的时候效率比较低,单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表 业务的边界不清晰,专库专用 虽然我们对应用系统做了大量的微服务处理,提升了系统在应用体系上的吞吐量,但是随着业务的越来越多,我们的数据库势必有不堪重负的一天,那么我们是怎么处理数据层的问题呢?这里就需要采用分库分表的策略来处理:
Sharding-jdbc是ShardingSphere的其中一个模块,定位为==轻量级Java框架==,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架 。
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。 Sharding-JDBC的核心功能为数据分片 和读写分离 ,通过Sharding-JDBC,应用可以透明 的使用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
第二章 分库分表方式 分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
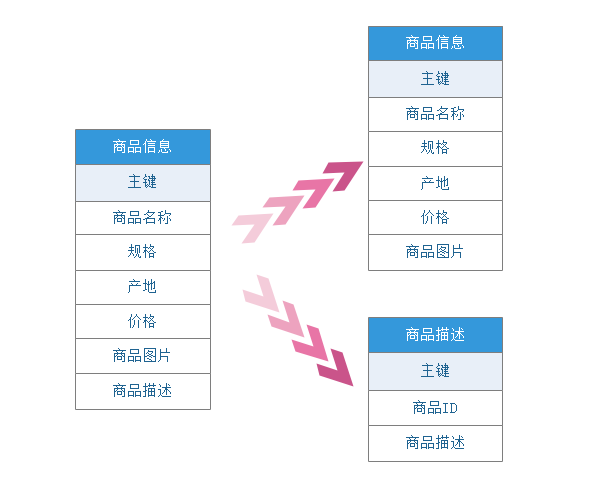
1、垂直分表 名词解释:将一个表按照字段分成多表,每个表存储其中一部分字段
它带来的提升是:
垂直拆分原则:
把不常用的字段单独放在一张表; 把text,blob等大字段拆分出来放在附表中; 经常组合查询的列放在一张表中; 2、垂直分库 名词解释:垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
通过垂直分表性能 得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器 ,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
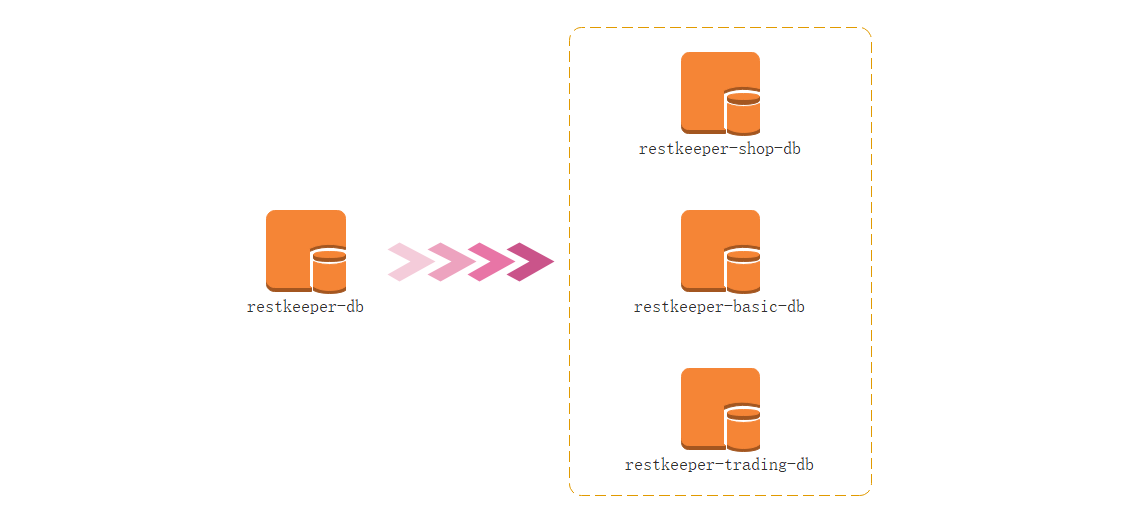
垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,它的核心理念 是专库专用。
它带来的提升是:
解决业务层面的耦合,业务清晰 能对不同业务的数据进行分级管理、维护、监控、扩展等 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈 垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多 个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
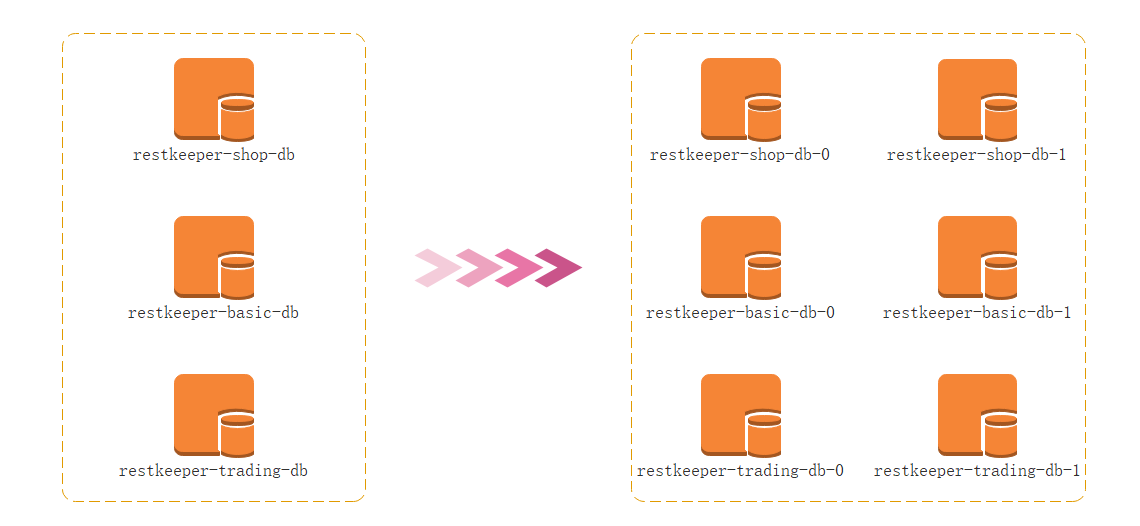
3、水平分库 名词解释:是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
经过垂直分库 后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,单库存储数据已经超出预估。
以电商网站为例:有8w店铺 ,每个店铺平均150个不同规格的商品,再算上增长,那商品数量得往1500w+上预估,并且商品库 属于访问非常频繁的资源,单台服务器已经无法支撑。此时该如何优化?
再次分库?但是从业务角度分析,目前情况已经无法再次垂直分库。
水平分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构。
思考:如何存储和访问数据库呢?
它带来的提升是:
解决了单库单表大数据,高并发的性能瓶颈。 提高了系统的稳定性及可用性 当一个应用难以再细粒度的垂直切分,或切分后数据量行数 巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库 了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
4、水平分表 水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
思考:如何存储和访问数据库中的表呢?
它带来的提升是:
优化单一表数据量过大而产生的性能问题 避免IO争抢并减少锁表的几率 库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
5、分库分表带来的问题 分库分表能有效的缓解了单机和单库带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来了一些问题。
事务一致性问题 跨节点关联查询 跨节点分页、排序函数 主键避重 公共表 6、小结 分库分表方式:垂直分表、垂直分库、水平分库和水平分表
垂直分表: 可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库: 可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
水平分库: 可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
水平分表: 可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
最佳实践:
一般来说,在系统设计阶段 就应该根据业务耦合松紧来确定垂直分库,垂直分表 方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术 等方案。若数据量极大,且持续增长,再考虑水平分库水平分表 方案。
第三章 sharding-jdbc架构 1、名词解释 参考官网-核心概念
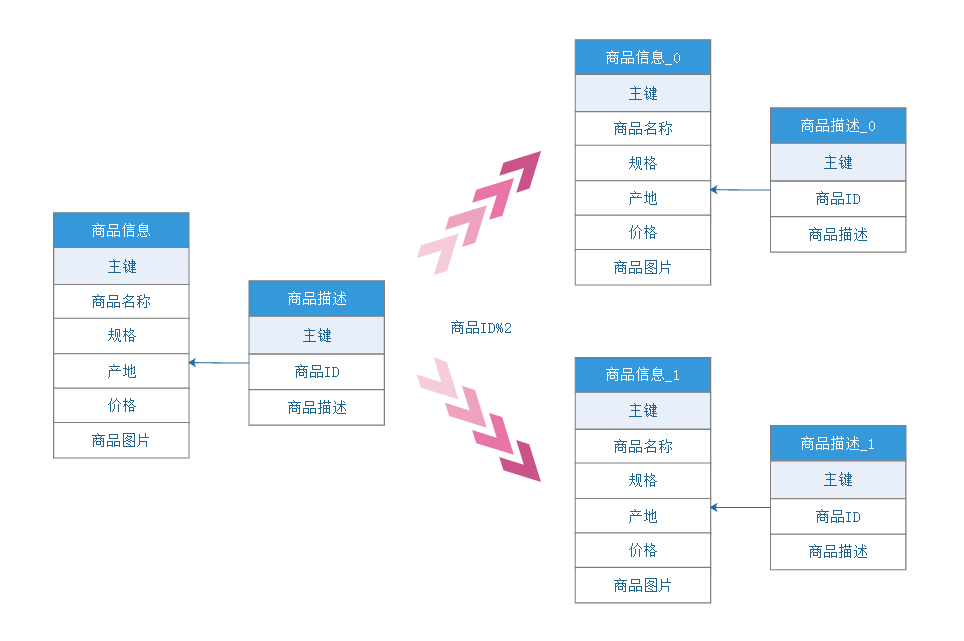
逻辑表(LogicTable):进行水平拆分的时候同一类型(逻辑、数据结构相同)的表的总称。例:用户数据根据主键尾数拆分为2张表,分别是tab_user_0到tab_user_1,他们的逻辑表名为tab_user。
真实表(ActualTable):在分片的数据库中真实存在的物理表。即上个示例中的tab_user_0到tab_user_1。
数据节点(DataNode):数据分片的最小单元。由数据源名称和数据表组成,例:spring-boot_0.tab_user_0,spring-boot_0.tab_user_1,spring-boot_1.tab_user_0,spring-boot_1.tab_user_1。
动态表(DynamicTable):逻辑表和物理表不一定需要在配置规则中静态配置。如,按照日期分片的场景,物理表的名称随着时间的推移会产生变化。
广播表(公共表):指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
绑定表(BindingTable):指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照`order_no分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
1 SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );
==让order的数据落库位置,与order_item落库的位置在同一个数据节点==
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
1 2 3 4 5 6 7 SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 ); SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 ); SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );
在配置绑定表关系后,路由的SQL应该为2条:
1 2 3 SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 ); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order`的条件。故绑定表之间的分区键要完全相同。
分片键 (ShardingColumn):分片字段用于将数据库(表)水平拆分的字段,支持单字段及多字段分片。例如上例中的order_id。
2、Sharding-JDBC执行原理
参考官网-内部剖析 :
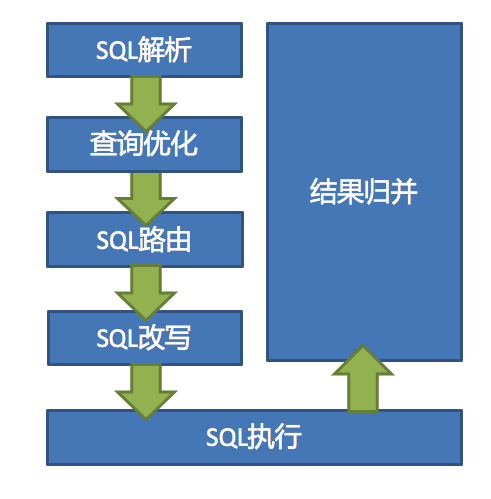
shardingSphere的3个产品的数据分片主要流程是完全一致的。 核心由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
例如现在有一条查询语句:
1 select * from t_user where id= 10
进行了分库分表操作,2个库ds0,ds1,采用的分片键为id,逻辑表为t_user,真实表为t_user_0、t_user_1两张表,分库、分表算法为均为取余(%2)。
sql解析:通过解析sql语句提取分片键列与值进行分片,例如比较符 =、in 、between and,及查询的表等。
执行器优化:合并和优化分片条件,如OR等。
sql路由:找到sql需要去哪个库、哪个表执行语句,上例sql根据采用的策略可以得到将在ds0库,t_user_0表执行语句。
sql改写:根据解析结果,及采用的分片逻辑改写sql,SQL改写分为正确性改写和优化改写。
上例经过sql改写后,真实语句为:
1 2 3 4 select * from ds0.t_user_0 where id= 10 ;= = > ds0.t_user_0 2 Sselect * from ds0.t_user_1 where id= 10 ;= = > ds0.t_user_1 2 Sselect * from ds1.t_user_0 where id= 10 ;= = > ds1.t_user_0 2 Sselect * from ds1.t_user_1 where id= 10 ;= = > ds1.t_user_1 2 S
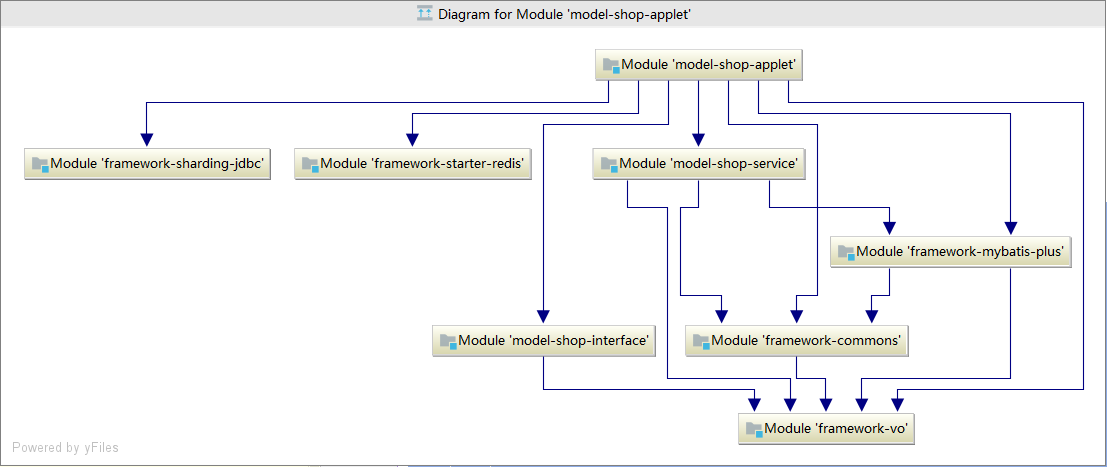
sql执行:通过多线程执行器异步执行。 结果归并:将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。 第四章 sharding-jdbc实战 那我们怎么使用这个插件呢?来我们看下我们项目中集成的framework-sharding-jdbc的模块:
1 2 |——restkeeper-framework 核心组件模块,集成:mybatis-plus、seata、jwt、redis等等 |————framework-sharding-jdbc关于sharding-jdbc基础集成
framework-sharding-jdbc 模块中我们需要导入对sharding-jdbc的支持:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <dependencies > <dependency > <groupId > org.apache.shardingsphere</groupId > <artifactId > sharding-transaction-xa-core</artifactId > </dependency > <dependency > <groupId > org.apache.shardingsphere</groupId > <artifactId > sharding-transaction-base-seata-at</artifactId > </dependency > <dependency > <groupId > org.apache.shardingsphere</groupId > <artifactId > sharding-jdbc-spring-boot-starter</artifactId > </dependency > </dependencies >
1、sharding-jdbc-集成并处理分布式事务 官网参考:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction
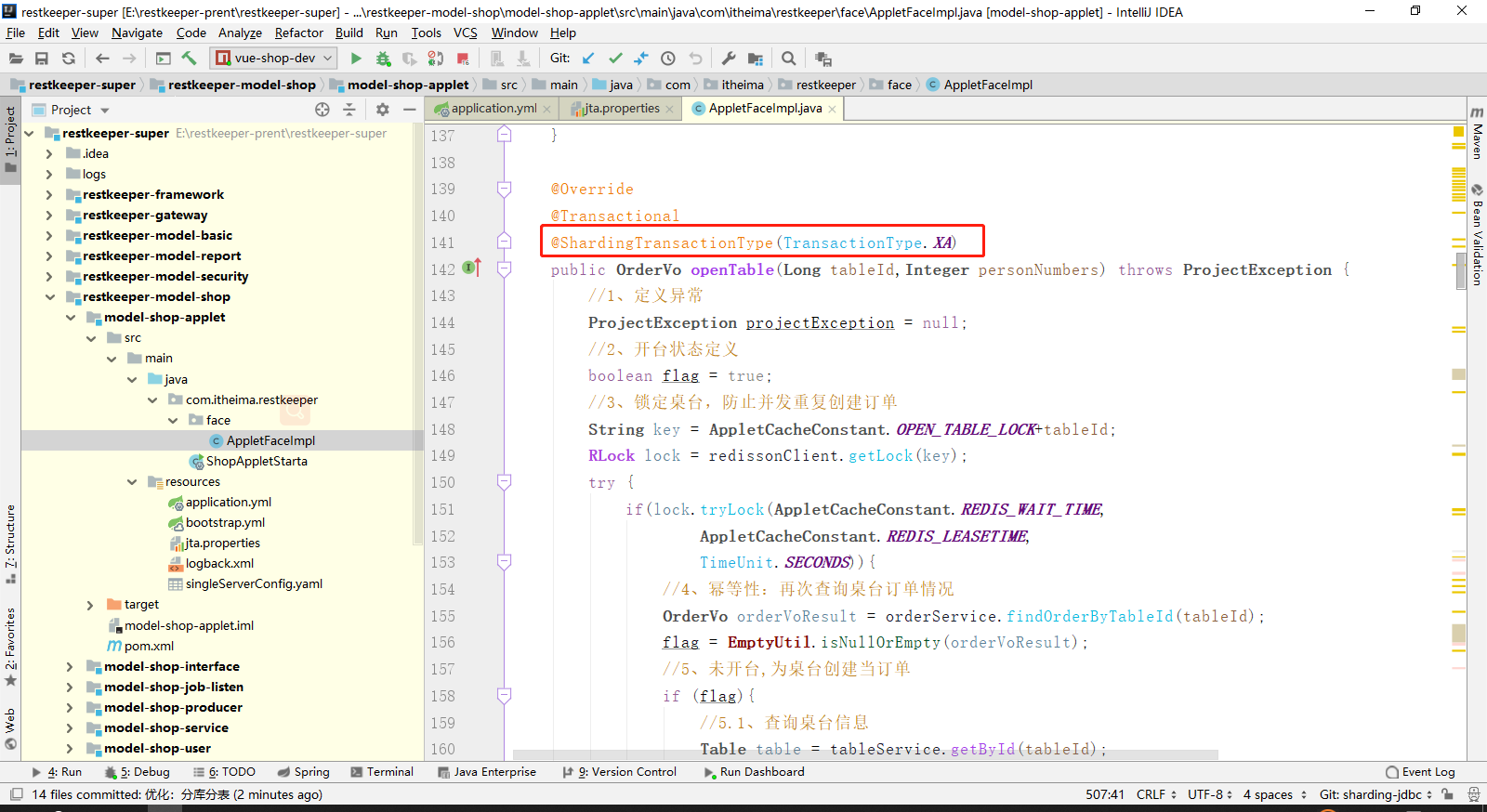
1.1、XA事务使用sharding-jdbc 以 model-shop-applet 项目为例
我们使用sharding-jdbc的时候只需要依赖: framework-sharding-jdbc 模块
1、排除druid-spring-boot-starter和sharding-transaction-base-seata-at的jar
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 <dependency > <groupId > com.itheima.restkeeper</groupId > <artifactId > model-security-service</artifactId > <exclusions > <exclusion > <artifactId > druid-spring-boot-starter</artifactId > <groupId > com.alibaba</groupId > </exclusion > </exclusions > </dependency > <dependency > <groupId > com.itheima.restkeeper</groupId > <artifactId > model-shop-service</artifactId > <exclusions > <exclusion > <groupId > com.alibaba</groupId > <artifactId > druid-spring-boot-starter</artifactId > </exclusion > </exclusions > </dependency > <dependency > <groupId > com.itheima.restkeeper</groupId > <artifactId > framework-sharding-jdbc</artifactId > <exclusions > <exclusion > <groupId > org.apache.shardingsphere</groupId > <artifactId > sharding-transaction-base-seata-at</artifactId > </exclusion > </exclusions > </dependency >
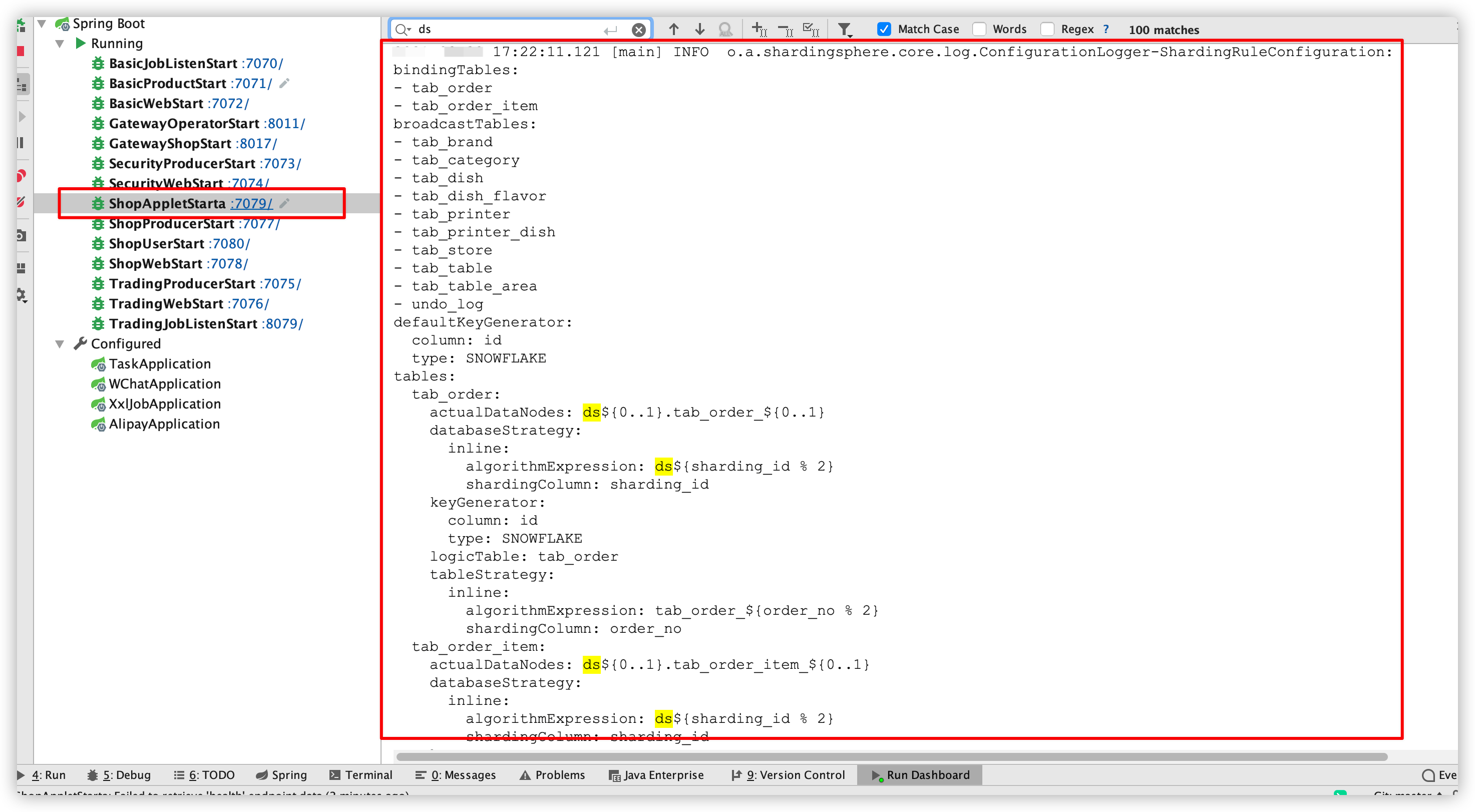
2、然后在model-shop-applet的application.yml中添加sharding-jdbc配置即可==【如果使用nacos配置中心,需要在配置中心中添加配置: model-shop-applet-prod.yml】==:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 server: port: 7079 tomcat: uri-encoding: UTF-8 spring: main: allow-bean-definition-overriding: true redis: redisson: config: classpath:singleServerConfig.yaml host: 192.168 .200 .129 port: 6379 password: pass jta: atomikos: properties: log-base-dir: logs/model-shop-applet-atomikos log-base-name: model-shop-applet shardingsphere: datasource: names: ds0,ds1 ds0: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.200.129:3306/restkeeper-shop-0?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8 username: root password: pass ds1: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.200.151:3306/restkeeper-shop-1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8 username: root password: root sharding: tables: tab_order: actualDataNodes: ds${0..1}.tab_order_${0..1} databaseStrategy: inline: shardingColumn: sharding_id algorithmExpression: ds${sharding_id % 2 } tableStrategy: inline: shardingColumn: order_no algorithmExpression: tab_order_${order_no % 2 } keyGenerator: type: SNOWFLAKE column: id tab_order_item: actualDataNodes: ds${0..1}.tab_order_item_${0..1} databaseStrategy: inline: shardingColumn: sharding_id algorithmExpression: ds${sharding_id % 2 } tableStrategy: inline: shardingColumn: product_order_no algorithmExpression: tab_order_item_${product_order_no % 2 } keyGenerator: type: SNOWFLAKE column: id binding-tables: - tab_order - tab_order_item broadcast-tables: - tab_brand - tab_category - tab_dish - tab_dish_flavor - tab_printer - tab_printer_dish - tab_store - tab_table - tab_table_area - undo_log default-key-generator: type: SNOWFLAKE column: id props: sql.show: true mybatis-plus: type-aliases-package: com.itheima.springcloud.pojo type-aliases-super-type: com.itheima.restkeeper.basic.BasicPojo configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl map-underscore-to-camel-case: true use-generated-keys: true default-statement-timeout: 60 default-fetch-size: 100 ignore-enterprise-tables: - tab_brand - tab_category - tab_dish - tab_dish_flavor - tab_order - tab_order_item - tab_printer - tab_printer_dish - tab_store - tab_table - tab_table_area - tab_role - tab_order_role - undo_log ignore-store-tables: - tab_brand - tab_category - tab_dish - tab_dish_flavor - tab_order - tab_order_item - tab_printer - tab_printer_dish - tab_store - tab_table - tab_table_area - tab_role - tab_order_role - undo_log logging: config: classpath:logback.xml dubbo: application: version: 1.0 .0 logger: slf4j scan: base-packages: com.itheima.restkeeper registry: address: spring-cloud://192.168.200.129 protocol: name: dubbo port: 27079 threads: 200 accesslog: logs/model-shop-applet-01.log
3、在 resources 文件夹下添加jta.properties
1 2 com.atomikos.icatch.output_dir =D:/atomikos/model-shop-applet com.atomikos.icatch.log_base_dir =D:/atomikos/model-shop-applet
4、指定事务分类刚性事务 :@ShardingTransactionType(TransactionType.XA)
5、启动服务测试,观察数据库数据添加情况,和控制台日志打印情况:
保存到数据库记录:
1.2、seata-at使用sharding-jdbc 以 model-shop-producer 项目为例
我们使用sharding-jdbc的时候只需要依赖: framework-sharding-jdbc 模块
1、排除 druid-spring-boot-starter 和sharding-transaction-xa-core的jar
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <dependency > <groupId > com.itheima.restkeeper</groupId > <artifactId > model-shop-service</artifactId > <exclusions > <exclusion > <groupId > com.alibaba</groupId > <artifactId > druid-spring-boot-starter</artifactId > </exclusion > </exclusions > </dependency > <dependency > <groupId > com.itheima.restkeeper</groupId > <artifactId > framework-sharding-jdbc</artifactId > <exclusions > <exclusion > <groupId > org.apache.shardingsphere</groupId > <artifactId > sharding-transaction-xa-core</artifactId > </exclusion > </exclusions > </dependency >
2、然后在model-shop-producer的application.yml中添加sharding-jdcb配置即可==【如果使用nacos配置中心,需要在配置中心中添加配置】==:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 server: port: 7077 tomcat: uri-encoding: UTF-8 spring: application: name: model-shop-producer main: allow-bean-definition-overriding: true redis: redisson: config: classpath:singleServerConfig.yaml host: 192.168 .200 .129 port: 6379 password: pass cloud: alibaba: seata: tx-service-group: project_tx_group jta: atomikos: properties: log-base-dir: logs/model-shop-producer-atomikos log-base-name: model-shop-producer shardingsphere: datasource: names: ds0,ds1 ds0: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.200.129:3306/restkeeper-shop-0?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8 username: root password: pass ds1: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.200.151:3306/restkeeper-shop-1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8 username: root password: root sharding: tables: tab_order: actualDataNodes: ds${0..1}.tab_order_${0..1} databaseStrategy: inline: shardingColumn: sharding_id algorithmExpression: ds${sharding_id % 2 } tableStrategy: inline: shardingColumn: order_no algorithmExpression: tab_order_${order_no % 2 } keyGenerator: type: SNOWFLAKE column: id tab_order_item: actualDataNodes: ds${0..1}.tab_order_item_${0..1} databaseStrategy: inline: shardingColumn: sharding_id algorithmExpression: ds${sharding_id % 2 } tableStrategy: inline: shardingColumn: product_order_no algorithmExpression: tab_order_item_${product_order_no % 2 } keyGenerator: type: SNOWFLAKE column: id binding-tables: - tab_order - tab_order_item broadcast-tables: - tab_brand - tab_category - tab_dish - tab_dish_flavor - tab_printer - tab_printer_dish - tab_store - tab_table - tab_table_area - undo_log default-key-generator: type: SNOWFLAKE column: id props: sql.show: true mybatis-plus: type-aliases-package: com.itheima.springcloud.pojo type-aliases-super-type: com.itheima.restkeeper.basic.BasicPojo configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl map-underscore-to-camel-case: true use-generated-keys: true default-statement-timeout: 60 default-fetch-size: 100 ignore-enterprise-tables: - tab_dish_flavor - tab_order_item - undo_log ignore-store-tables: - tab_dish_flavor - tab_brand - tab_order_item - tab_store - undo_log seata: tx-service-group: project_tx_group enabled: true application-id: ${spring.application.name} enable-auto-data-source-proxy: false service: vgroup-mapping: project_tx_group: default grouplist: default: 192.168 .200 .129 :9200 config: type: nacos nacos: group: SEATA_GROUP server-addr: 192.168 .200 .129 :8848 username: nacos password: nacos registry: type: nacos nacos: group: SEATA_GROUP server-addr: 192.168 .200 .129 :8848 username: nacos password: nacos dubbo: application: version: 1.0 .0 logger: slf4j scan: base-packages: com.itheima.restkeeper registry: address: spring-cloud://192.168.200.129 protocol: name: dubbo port: 27077 threads: 200 accesslog: logs/model-shop-producer-01.log
3、添加jta.properties
1 2 com.atomikos.icatch.output_dir =D:/atomikos/model-shop-producer com.atomikos.icatch.log_base_dir =D:/atomikos/model-shop-producer
4、在resources路径下添加seata.conf
1 2 3 4 client { application.id = model-shop-producer transaction.service.group = project_tx_group }
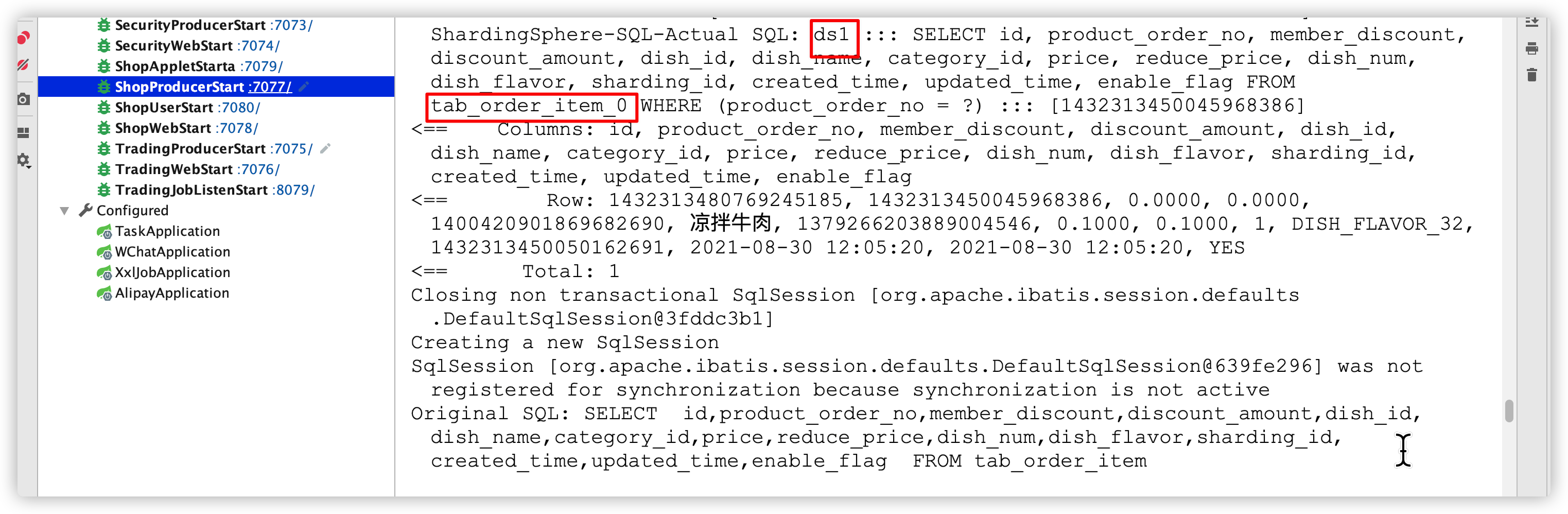
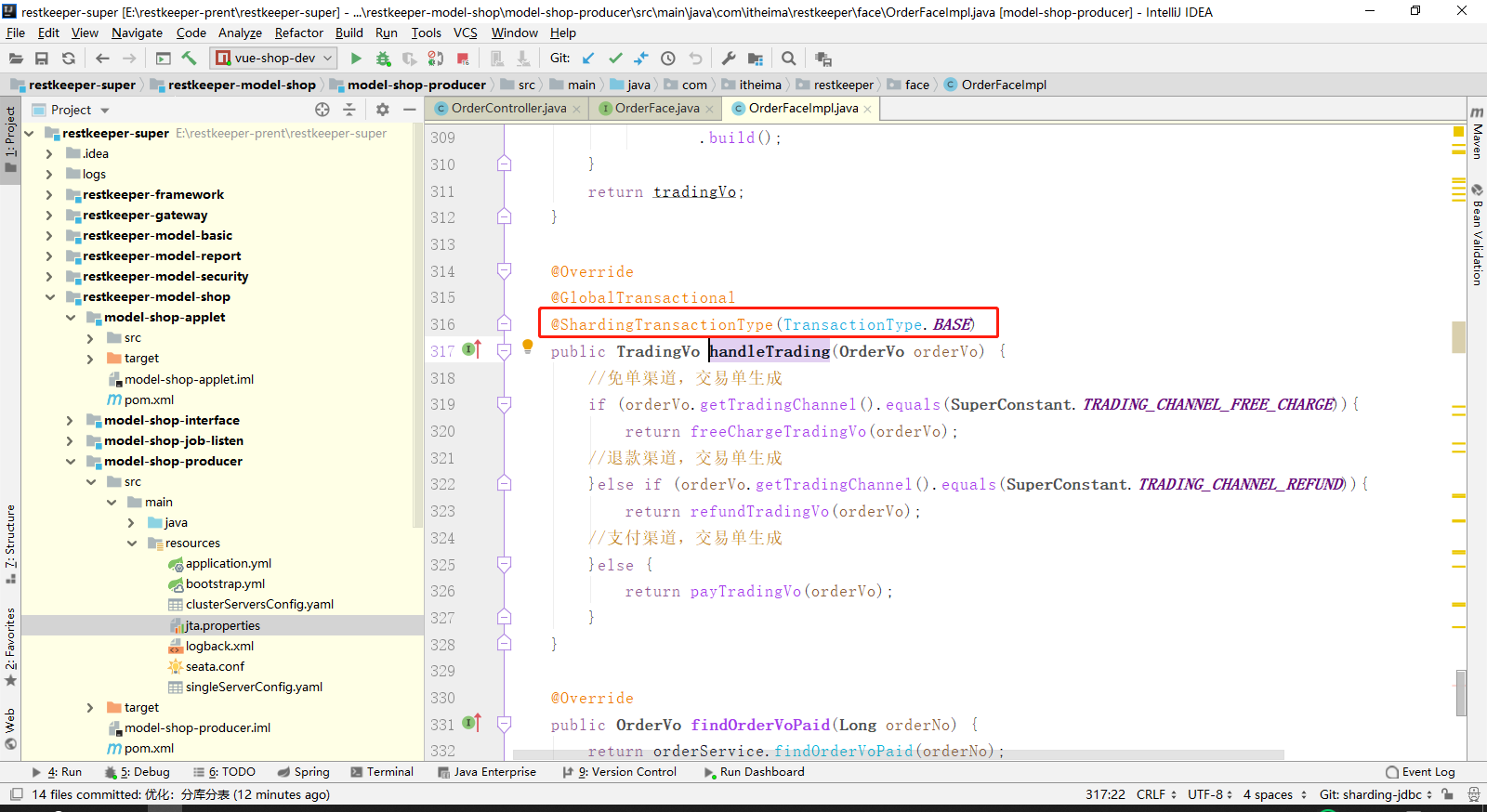
5、指定事务分类(柔性事务):@ShardingTransactionType(TransactionType.BASE)
6、测试下单结算成功后,执行XXl-JOB任务查询订单结算状态出现以下bug:
问题分析:
Sharding-JDBC中分片键一旦设置成功,是不允许被修改的。 解决方案:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Override @GlobalTransactional public Boolean synchTradingState (Long orderNo, String tradingState) { OrderVo orderVo = orderService.findOrderByOrderNo(orderNo); if (EmptyUtil.isNullOrEmpty(orderVo)) { throw new ProjectException (ShoppingCartEnum.UPDATE_ORDER_FAIL); } orderVo = OrderVo.builder() .id(orderVo.getId()) .orderState(tradingState).build(); return orderService.saveOrUpdate(BeanConv.toBean(orderVo,Order.class)); }
2、分库键回填机制 在BasicPojo中添加分片字段shardingId
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package com.itheima.springcloud.basic;import com.baomidou.mybatisplus.annotation.FieldFill;import com.baomidou.mybatisplus.annotation.TableField;import com.fasterxml.jackson.annotation.JsonFormat;import com.itheima.springcloud.utils.ToString;import lombok.AllArgsConstructor;import org.apache.commons.lang3.builder.ToStringBuilder;import org.apache.commons.lang3.builder.ToStringStyle;import org.springframework.format.annotation.DateTimeFormat;import java.util.Date;@AllArgsConstructor public class BasicPojo extends ToString { public BasicPojo () { } public BasicPojo (Long id) { this .id = id; } @JsonFormat(shape = JsonFormat.Shape.STRING) private Long id; @TableField(fill = FieldFill.INSERT) protected Long shardingId; @TableField(fill = FieldFill.INSERT) @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") @JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8") protected Date createdTime; @TableField(fill = FieldFill.INSERT_UPDATE) @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") @JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8") protected Date updatedTime; public Long getId () { return id; } public void setId (Long id) { this .id = id; } public Date getCreatedTime () { return createdTime; } public void setCreatedTime (Date createdTime) { this .createdTime = createdTime; } public Date getUpdatedTime () { return updatedTime; } public void setUpdatedTime (Date updatedTime) { this .updatedTime = updatedTime; } public String toString () { return ToStringBuilder.reflectionToString(this , ToStringStyle.SHORT_PREFIX_STYLE); } }
MyBatisMetaObjectHandler中添加shardingId回填
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.itheima.springcloud.handler;import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;import com.itheima.springcloud.utils.SnowflakeIdWorker;import lombok.extern.slf4j.Slf4j;import org.apache.ibatis.reflection.MetaObject;import org.springframework.beans.factory.annotation.Autowired;import java.util.Date;@Slf4j public class MyBatisMetaObjectHandler implements MetaObjectHandler { @Autowired SnowflakeIdWorker snowflakeIdWorker; @Override public void insertFill (MetaObject metaObject) { log.info("开始插入填充....." ); Object shardingId = getFieldValByName("shardingId" , metaObject); if (metaObject.hasSetter("shardingId" )&&shardingId==null ) { this .strictInsertFill(metaObject, "shardingId" , Long.class,snowflakeIdWorker.nextId() ); } if (metaObject.hasSetter("createdTime" )) { this .strictInsertFill(metaObject, "createdTime" , Date.class, new Date ()); } if (metaObject.hasSetter("updatedTime" )) { this .strictInsertFill(metaObject, "updatedTime" , Date.class, new Date ()); } } @Override public void updateFill (MetaObject metaObject) { log.info("开始更新填充....." ); if (metaObject.hasSetter("updatedTime" )) { this .strictUpdateFill(metaObject, "updatedTime" , Date.class, new Date ()); } } }
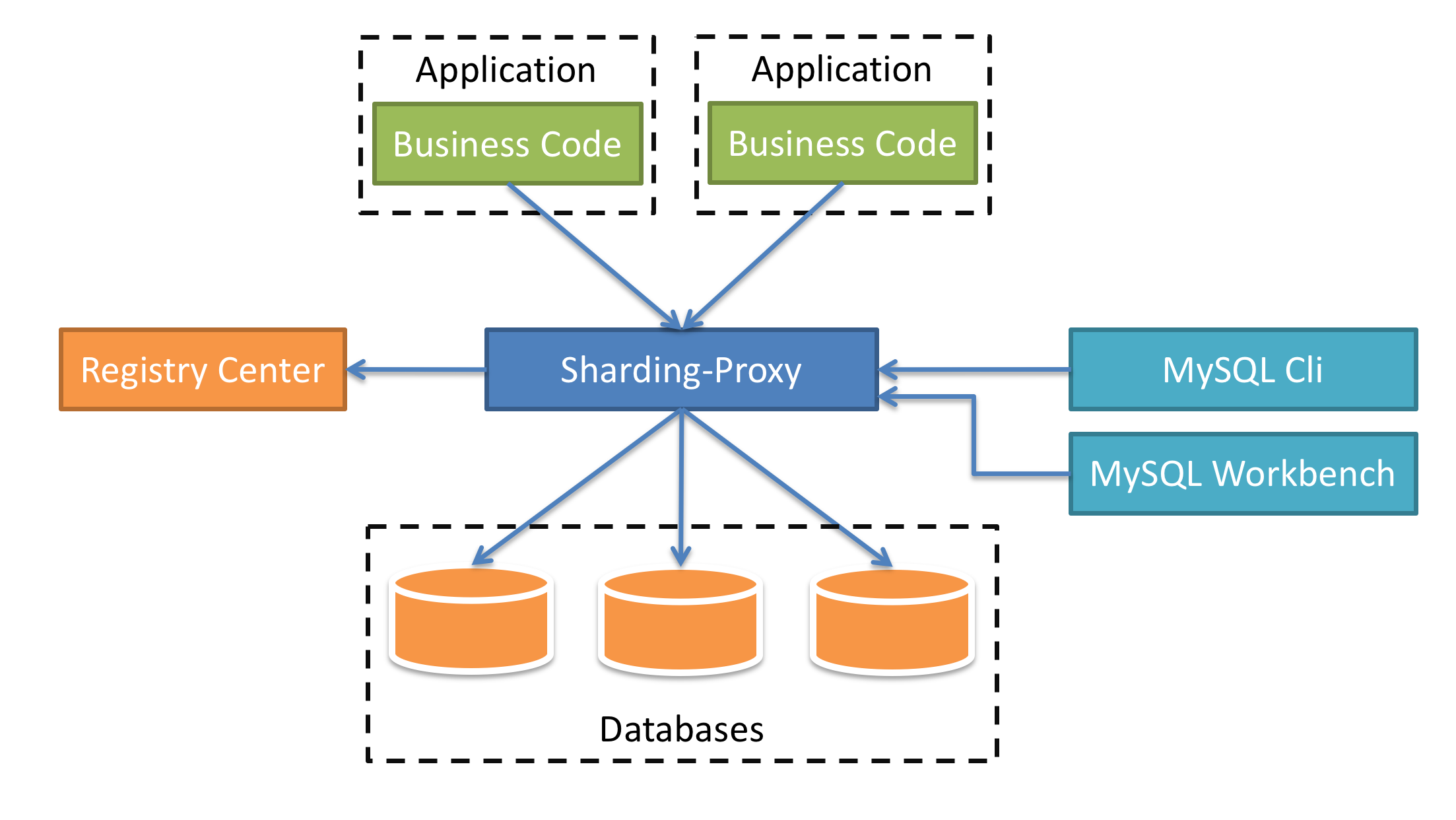
第五章 sharding-proxy实战 1、Sharding-Proxy简介 Sharding-Proxy 是ShardingSphere的第二个产品。 它定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。
向应用程序完全透明,可直接当做MySQL/PostgreSQL使用。 适用于任何兼容MySQL/PostgreSQL协议的的客户端。
JDBC和Proxy对比:
维度 Sharding-JDBC Sharding-Proxy 数据库 任意 MySQL/PostgreSQL连接消耗数 高 低异构语言 仅Java 任意性能 损耗低 损耗略高无中心化 是 否静态入口 无 有
Sharding-Proxy的优势在于对异构语言的支持,以及为DBA提供可操作入口。
2、sharding-proxy快速入门 1、下载sharding-proxy 执行的软件包
下载连接地址:https://archive.apache.org/dist/shardingsphere/
2、编辑配置文件:server.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 authentication: users: root: password: root sharding: password: sharding authorizedSchemas: sharding_db props: max.connections.size.per.query: 1 acceptor.size: 16 executor.size: 16 proxy.frontend.flush.threshold: 128 proxy.transaction.type: LOCAL proxy.opentracing.enabled: false proxy.hint.enabled: false query.with.cipher.column: true sql.show: true allow.range.query.with.inline.sharding: false
3、编辑配置文件:config-sharding.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 schemaName: sharding_db dataSources: ds_0: url: jdbc:mysql://192.168.200.129:3306/restkeeper-shop-0?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8 username: root password: pass connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 ds_1: url: jdbc:mysql://192.168.200.151:3306/restkeeper-shop-1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8 username: root password: root connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 shardingRule: tables: tb_order: actualDataNodes: ds_${0..1}.tb_order_${0..1} tableStrategy: inline: shardingColumn: order_no algorithmExpression: tb_order_${order_no % 2 } keyGenerator: type: SNOWFLAKE column: id tb_order_item: actualDataNodes: ds_${0..1}.tb_order_item_${0..1} tableStrategy: inline: shardingColumn: order_no algorithmExpression: tb_order_item_${order_no % 2 } keyGenerator: type: SNOWFLAKE column: id bindingTables: - tb_order,tb_order_item defaultDatabaseStrategy: inline: shardingColumn: sharding_id algorithmExpression: ds_${sharding_id % 2 } defaultTableStrategy: none:
4、添加mysql驱动包到lib目录
5、启动服务
1 ${sharding-proxy} \bin\start.sh
1 ${sharding-proxy} \bin\start.sh ${port}
6、使用cmd黑窗口连接测试建表
1 mysql - P3307 - h127.0 .0 .1 - p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 mysql> show databases; + | Database | + | sharding_db | + 1 row in set (0.00 sec)mysql> use sharding_db Database changed mysql> mysql> mysql> mysql> show tables; Empty set (0.01 sec)mysql> mysql> mysql> CREATE TABLE `tb_order` ( - > `id` bigint (18 ) NOT NULL COMMENT '' , - > `order_no` bigint (18 ) NOT NULL COMMENT '' , - > `sharding_id` bigint (18 ) NOT NULL COMMENT '' , - > `store_id` bigint (18 ) NOT NULL COMMENT 'id' , - > PRIMARY KEY (`id`) - > ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; Query OK, 0 rows affected (0.16 sec) mysql>
建表sql语句:
1 2 3 4 5 6 7 CREATE TABLE `tb_order` ( `id` bigint (18 ) NOT NULL COMMENT '' , `order_no` bigint (18 ) NOT NULL COMMENT '' , `sharding_id` bigint (18 ) NOT NULL COMMENT '' , `store_id` bigint (18 ) NOT NULL COMMENT 'id' , PRIMARY KEY (`id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4;
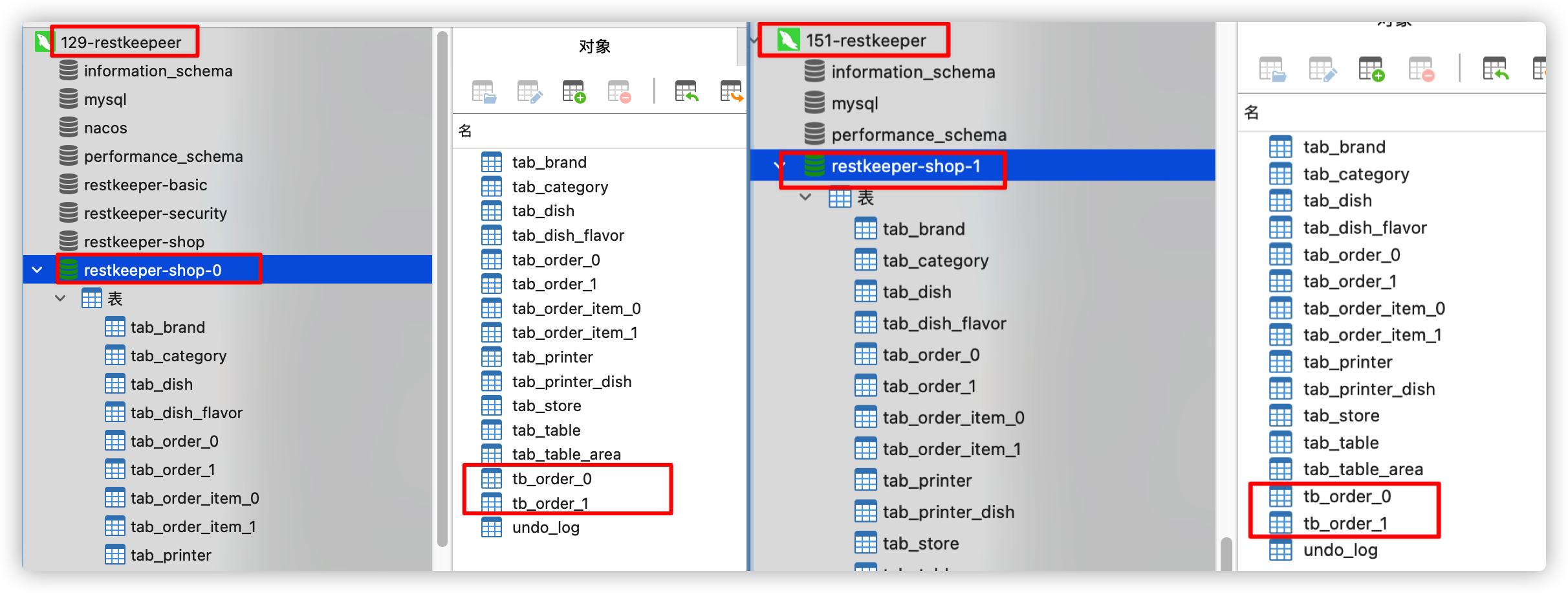
客户端查看效果:
3、SpringBoot集成sharding-proxy 1、搭建测试工程引入pom依赖
2、导入基础工程
3、测试代码